Database Architectures
Little background on the blog post.
I want to read a couple of books and possibly some research papers on this topic. Ever since I first introduced database systems in my CS grad course I liked data systems a lot.
They combine data structures, smart system programming architecture design, language analyzers, concurrency control, locking, transactions, in-memory storage, operating systems and appropriate use of data structures for real system software.
This was the real system software I saw as my first experience. Maybe one day I will build a system that will solve very niche but crucial problems for the companies I work for.
This is a huge topic. It took me days to read and write this blog post. This is not a perfect blog post but something I took notes on while I was re-learning about them. I enjoyed it. I hope you also do.
There are many things I want to write in detail about the database system, I want to keep it short and easy.. Maybe I will revisit them again, maybe build a database from scratch in the near future.
Database Architectures
Types of Database systems
- centralized database system
- decentralized database system
- parallel database system
- distributed database system
Centralized database systems
Are widely used, enterprise-scale applications.
Add shared everything architecture diagram
Decentralized database systems
Parallel database systems
Used for high end enterprise applications, Requirement for the transaction processing performance,
Primperly designed for retrieving petabytes of data ( 10^24 )
Pros
- Nodes are physically close to each other
- Nodes are connected with high-speed LAN
- Communication cost between nodes is assumed to be small
- No need to worry about node crashing
- Not an issue with packet dropping with internal protocol
Distributed database systems
Primparly for executing queries and update transactions across multiple databases,
Distributed techniques such as fault tolerance is a key role, extremely high reliability and availability
Another name for distributed database systems I call it online transaction processing ( OLTP ) systems to achieve faster data ingestion. For faster data ingestion another system designed called online analytical processing ( OLAP )
I listed some concepts that are covered in the distributed database systems that are very hard problems to solve in distributed data systems.
- Data Partitions
- Logical partition
- Physical partition
- Consistent hashing
- Distributed concurrency control
- Centralized co-ordinators
- Middleware
- Federated databases
- Replication
- Atomic commit protocols
- 2PC
- 3PC
- PAXOS
- ZAP
- RAFT
- CAP theorem
I will discuss this topic when I share a blogpost on distributed systems. They are fun.
Challenges
- Nodes can be far from each other
- Nodes are potentially connected via a public network slow and unreliable
- Communication cost
- Connection problems
- Node crash
- Packet drops
System architectures
The diagrams explain themselves.
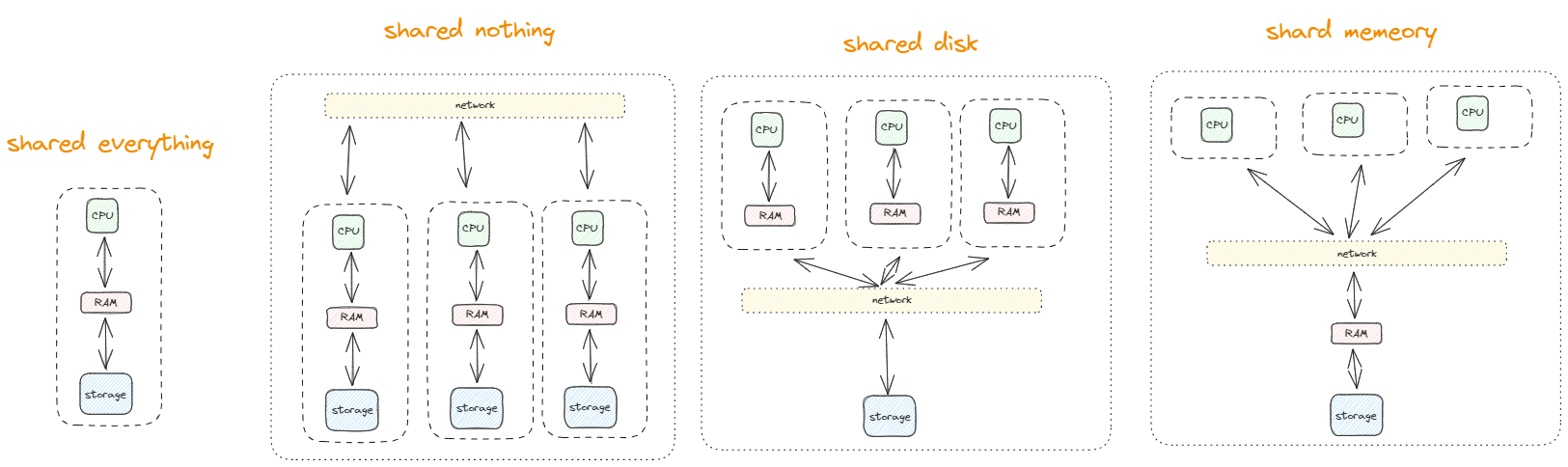
There is a correlation between the systems architectures and database systems design to each systems architectures.
| Architecture Type | Centralized DB Systems | Decentralized DB Systems | Parallel DB Systems | Distributed DB Systems |
|---|---|---|---|---|
| Shared Everything | ✅ | ❌ | ✅ | ❌ |
| Shared Memory | ✅ | ❌ | ✅ | ❌ |
| Shared Disk | ✅ | ❌ | ✅ | ✅ |
| Shared Nothing | ❌ | ✅ | ✅ | ✅ |
architecture diagrams
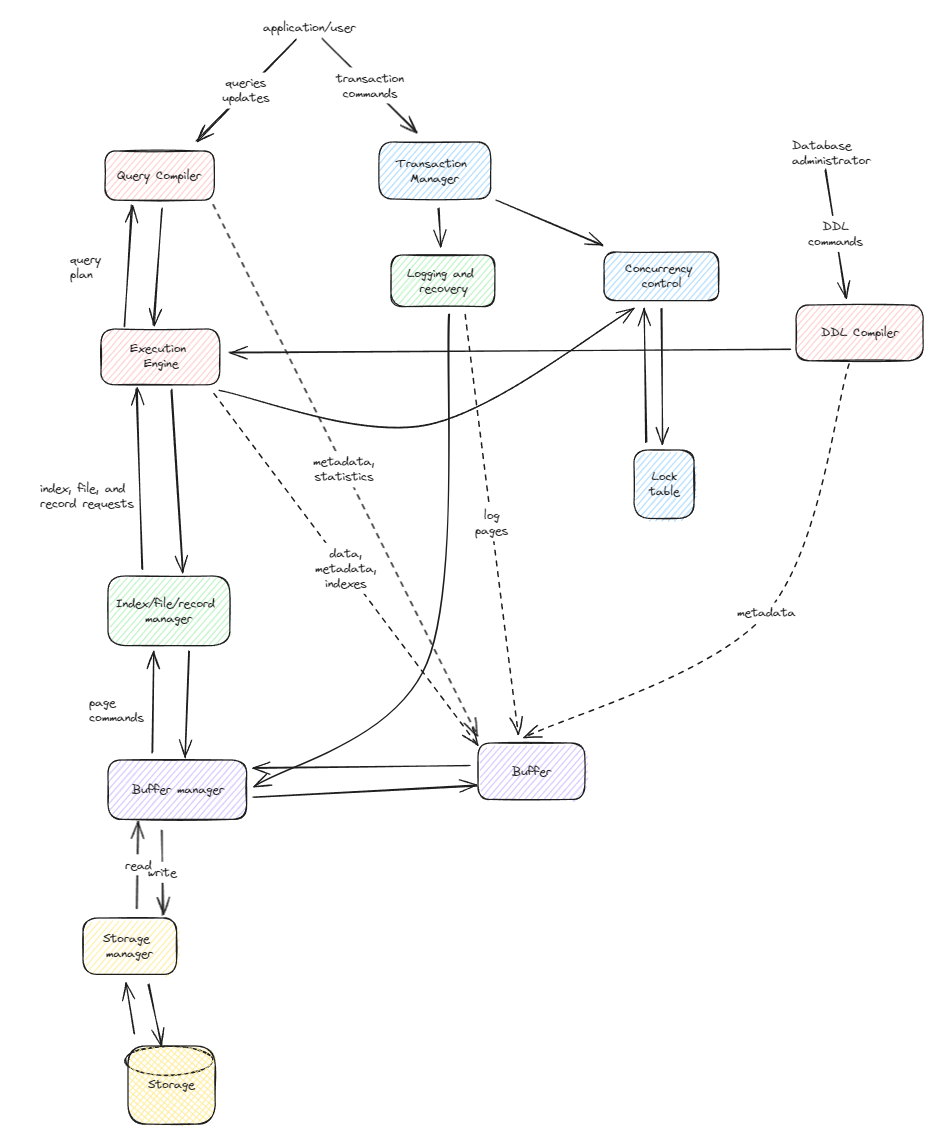
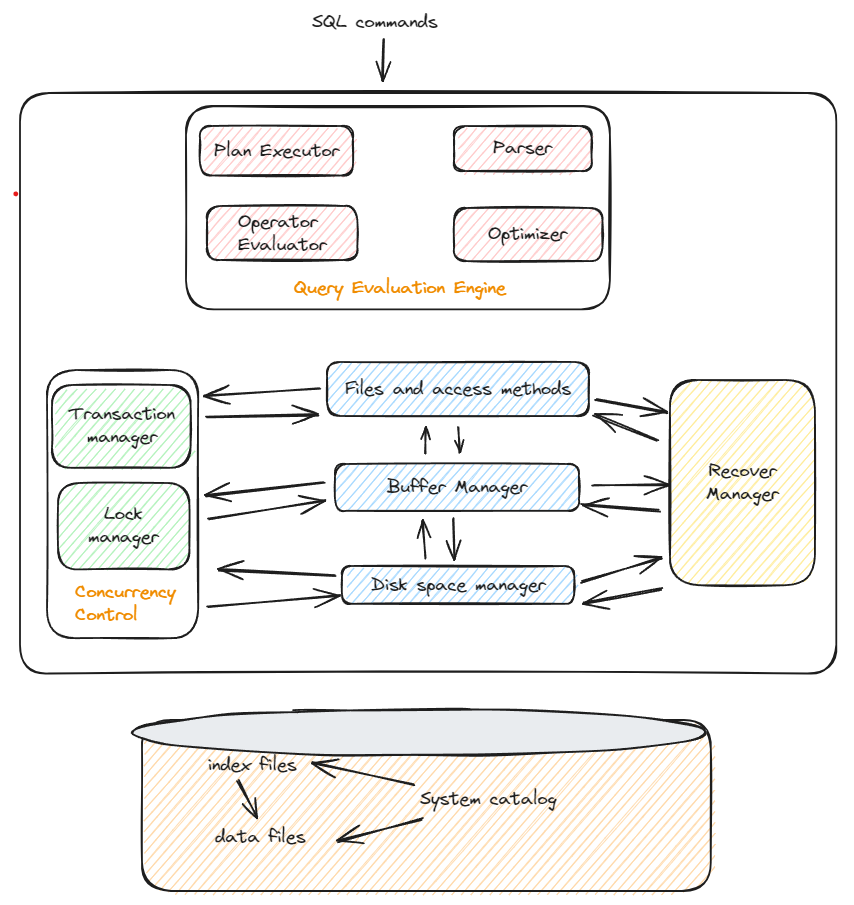
A user query is parsed query is presented to a query optimizer
Query optimizer uses information about how the data is stored to produce an efficient execution plan for evaluating the query, also it deals with the reordering of operations, elimination of redundancies and use of effective search algorithms during execution.
An execution plan is a blueprint for evaluating a query. Usually represented as a tree of relational operators
Relational operators then fetch a file as a collection of pages or collection of records, Heap file or files of unordered pages. As well as indexes are supported.
Organizes information in a page
The fields are accessed with buffer manager, which brings pages in form disk to main memory as per read request. This will have an effect on performance when we are reading and writing I/0 from a disk. Reducing disk R/W improves performance.
Transactions work with the system catalog and may update it with statistics.
Disk space manager does allocation and deallocation, reading and writing pages.
Storage manager
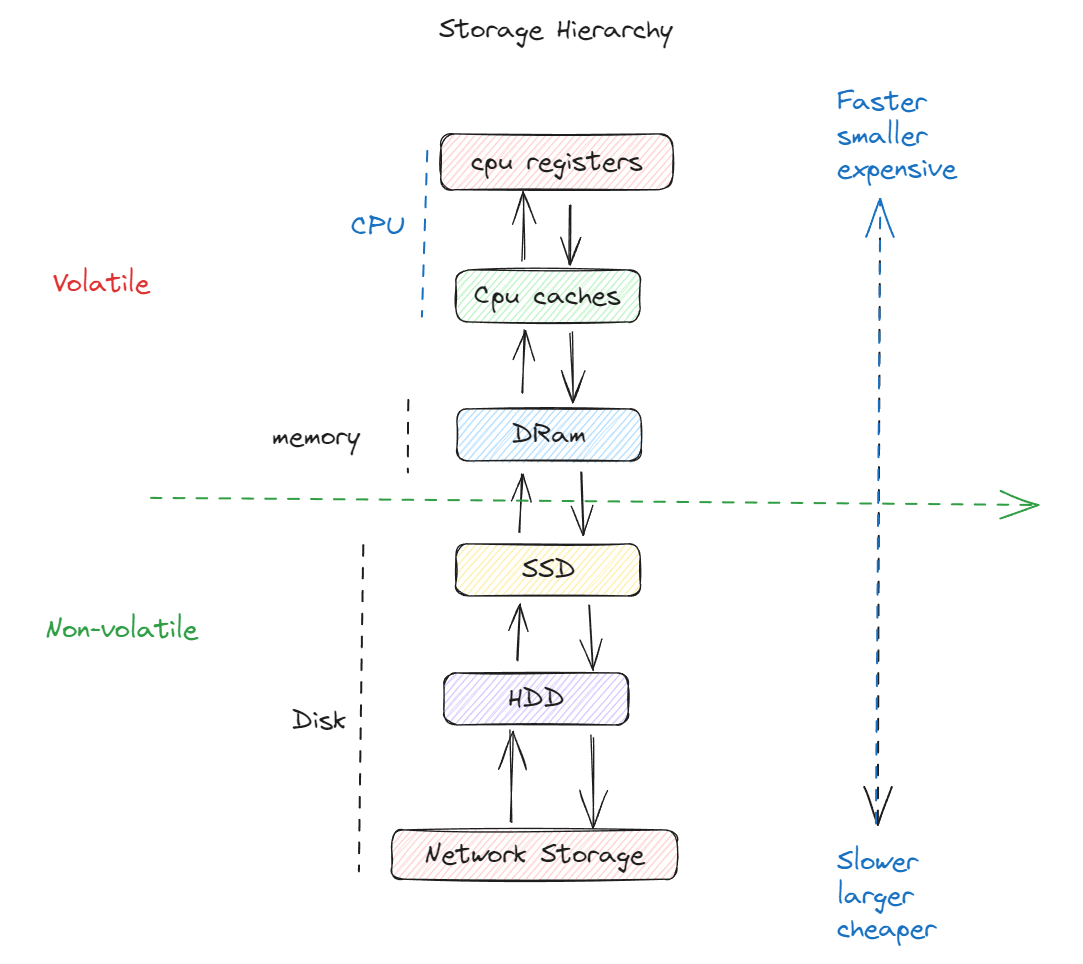
Storage Hierarchey
Latency Numbers
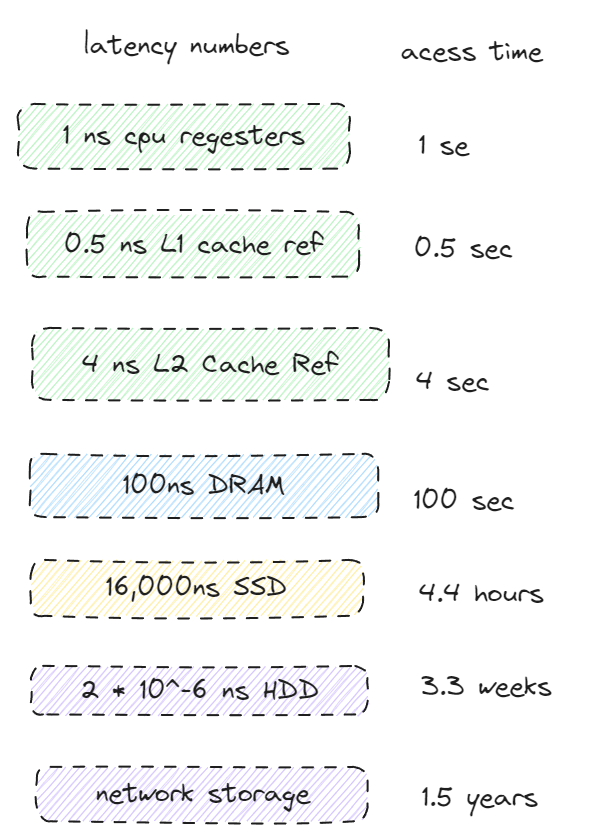
| Component | Latency (seconds) | Latency (scientific notation) | Time Analog (Human Scale) |
|---|---|---|---|
| CPU Register | 1 ns | 1 × 10⁻⁹ s | 1 second |
| L1 Cache | 0.5 ns | 5 × 10⁻¹⁰ s | 0.5 seconds |
| L2 Cache | 7 ns | 7 × 10⁻⁹ s | 7 seconds |
| Main Memory (DRAM) | 100 ns | 1 × 10⁻⁷ s | ~3 minutes |
| SSD (NVMe) | 100 µs | 1 × 10⁻⁴ s | ~2.8 hours |
| HDD | 10 ms | 1 × 10⁻² s | ~4.6 days |
| Network Storage | 100 ms | 1 × 10⁻¹ s | ~1.2 months |
| Tape Archive | 60 s | 6 × 10¹ s | ~6 years |
Volatile devices - RAM, CPU cache
When a system loses power the data will be lost in the case of a crash.
Supports fast random access
Non-volatile devices - disk
A typical harddrive which can hold data in absence of electricity.
Good at reading sequential access.
Supports block-page storages.
File manager
Buffer manager
Data in database files is organized into pages, DBMS uses a buffer pool to bring the pages from disk to memory. Buffer pool manages moving data from disk to memory.
Execution engine will be communicating with the buffer pool, and will give pointers to the memory.
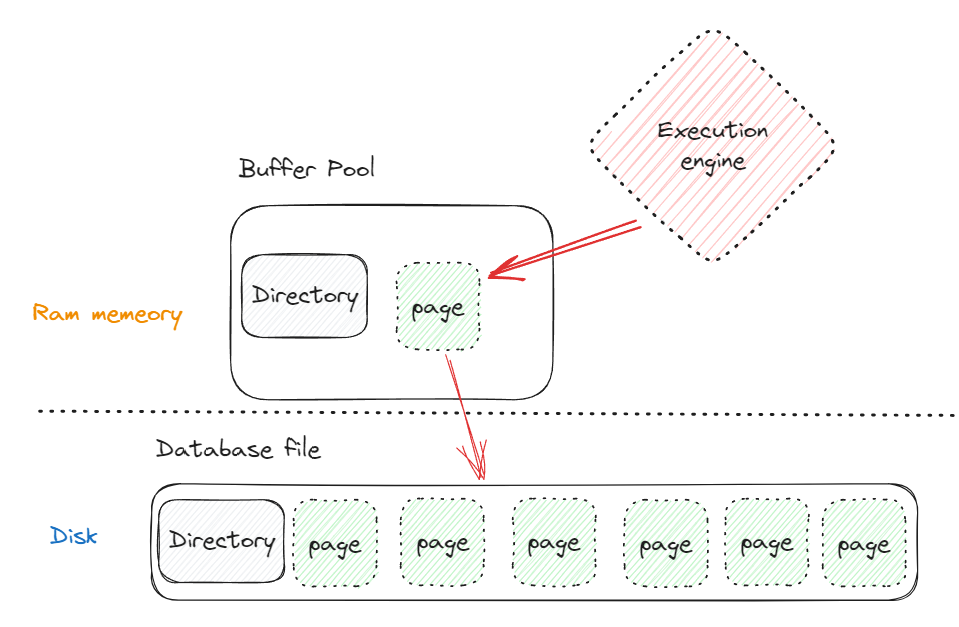
Database pages
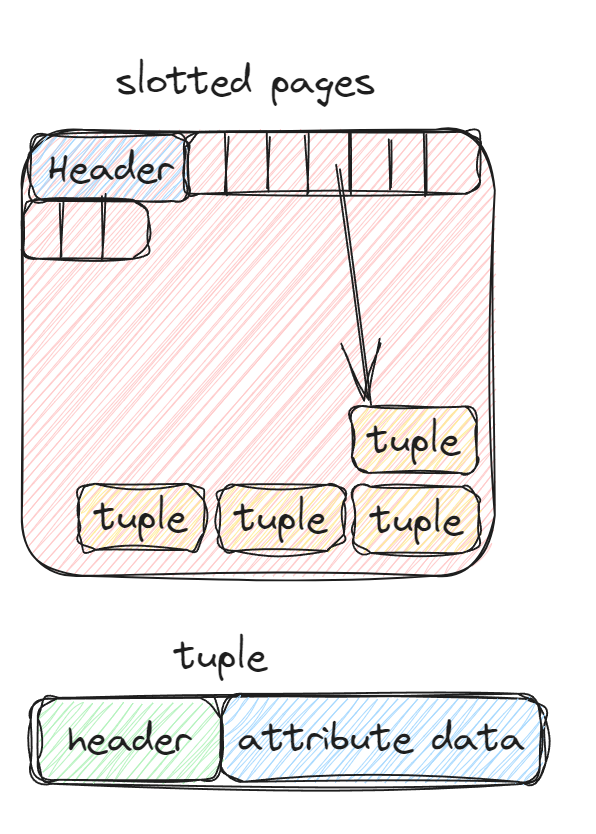
Fixed size block of data called pages. Usually page contains data ( tuples, indexes )
Each page will have a Unique identifier - page id, every database has its own implementation of pages, different databases can not read other database pages/files.
A layer that maps page id to a file path and offset
The hardware guarantees the atomic write.
Heap
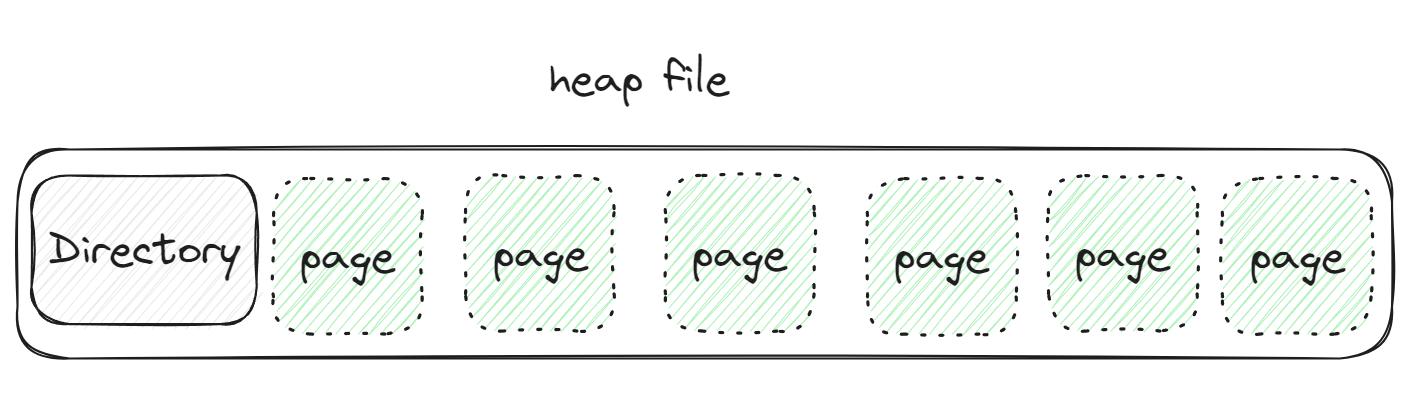
A heap file is an unordered collection of pages where tuples/records are stored in random order.
Finding the location of pages in DBMS, Uses linked list or page directory with help of page_id.
Linked list - header page holds the pointer to a list of free pages, list of data pages.
Does sequential scan for reading data page
Page directory tracks the location of pages, amount of free space on each page, free and empty pages, type of page
Todo :
- Add page directory diagram.
Strawman approach - Page layout
- Page size
- Checksum
- Database version
- Transaction visibility
Approche one - slotted pages.
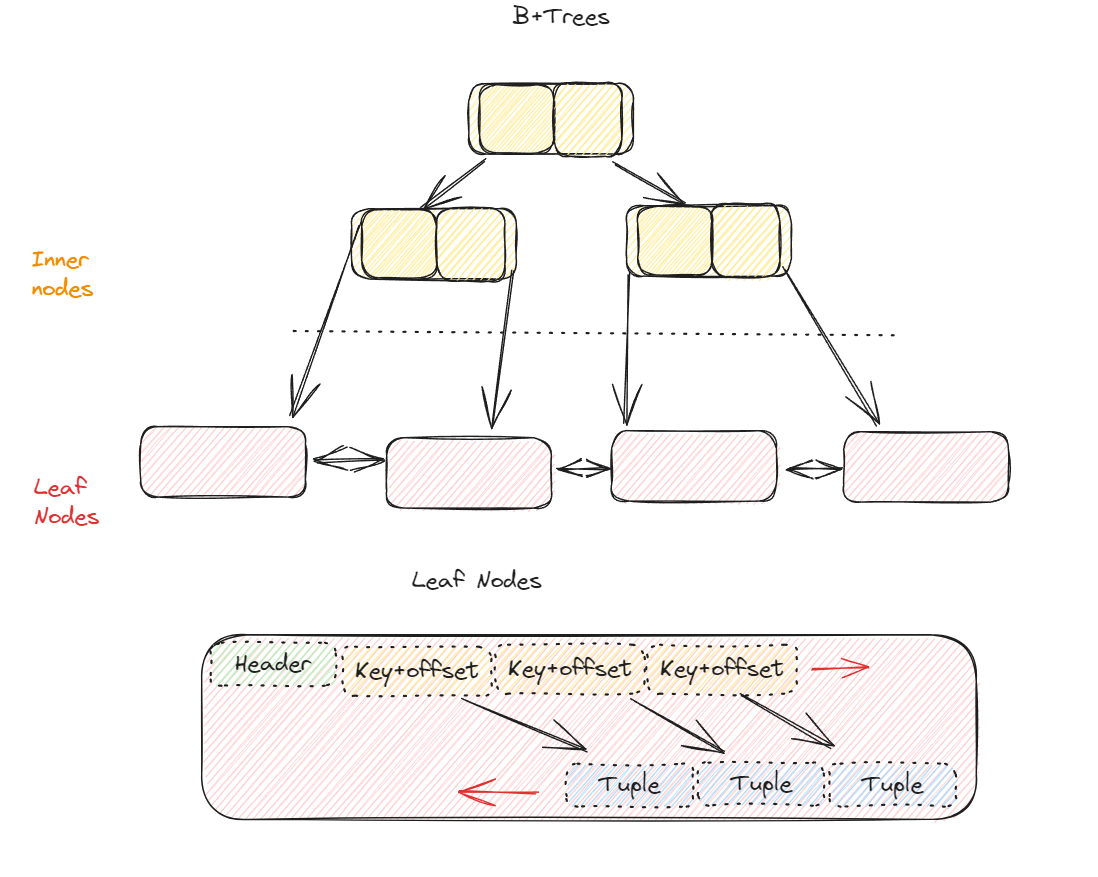
Page maps slots to offsets.
Header tracks the number of used slots, offset of starting location of the last used slot,
Slot array tracks of location of start of each tuple
When we add a tuple the slot array will grow from start to end, data of tuples will grow from end to start
Page is full when the slot array and tuple meet.
Approach two - log structured.
LSMT trees pretty much.
Tuple layout or record layout
Tuple header
Contains Metadata about tuple
Concurrency protocol
Bitmap for NULL value
Tuple data
Attributes stored int the order that we specify them in create DDL command, table structure. We cannot exceed the size of the page.
Unique id
Each tuple will have a unique id
Page+id + offset/slot
Denormalized tuple data
Since data stays on the same page, reading becomes faster. But makes the updates more expensive.
Query processor
Query plan operators in the query plan are arranged in a tree,
Data flows from leaves to the root.
Query Processing models how the system executes the query plan. Control flow, data flow.
Iterator model or pipeline model used in row-basd
Materialization model is a specialized iterator model
Vectorized or batch model emits a batch of data.
Access methods how DBMS access stored in a table
Sequential scan iterates over every page in the table and retrieves it from the buffer pool
Index scan picks an index to find the tuple that a query needs.
Multi index scan
Query Execution
Query execution with single worker or usually parallel with multiple workers.
Parallel execution
- Increased performance in throughput
- Increased responsiveness and availability
- Lower cost of ownership ( tco)
Query Planning and optimization
Two high level strategies for query optimization,
- Static rules or heuristics use catalogs to understand the structure of the data.
- Cost-based search to read and estimate the cost of executing. With statistics. histograms
Relational Algebra Operators
| Symbol | Operator |
|---|---|
| σ (sigma) | Selection |
| π (pi) | Projection |
| × | Cartesian Product |
| ⋈ | Natural Join |
| ⨝ | Theta Join |
| ∪ | Union |
| ∩ | Intersection |
| − | Difference |
| ρ (rho) | Rename |
| δ (delta) | Duplicate Elimination |
Physical Query Execution Operators
| Symbol | Operator |
|---|---|
| → (arrow) | Pipeline Execution |
| ⨯ | Nested Loop Join |
| ⋉ | Hash Join |
| ▷ | Merge Join |
| ⎔ (semi-join) | Semi-Join |
| ⎓ (anti-join) | Anti-Join |
Set and Sorting Operations
| Symbol | Operator |
|---|---|
| γ (gamma) | Group By |
| τ (tau) | Sorting |
| ⋃ (cup) | Set Union |
| ⋂ (cap) | Set Intersection |
| ∖ | Set Difference |
Access Operators in Execution Plans
| Symbol | Operator |
|---|---|
| 🗲 (lightning bolt) | Index Seek |
| ⬇ | Table Scan |
| ↔ | Index Scan |
| ↑ | Sort |
| ⤴ | Fetch |
Transaction manager and recovery
![]()
Transaction is the execution of a sequence of one or more operations on a shared database to perform some higher level function.
- Atomicity - all or nothing
- Consistency - it looks correct to me
- Isolation - all by myself
- Durability - i will survive
Atomicity - transaction either executes all its actions or non of them
Approach - one - logging
Logs all actions, so that it can undo the actions in case of aborted transactions.
Uses undo records but in memory and on disk
Approche - two - shadow paging
Make copies of pages modified by the transaction and translation and make changes to those copies.
Consistency - all queries about data will return logically correct results
Database consistency
Transaction consistency
Isolation - isolated transaction in a serial order
Executes in serial order but achieves better performance, has interleave the operations of concurrent transactions while maintaining the isolation.
Concurrency control protocol how a DBMS decides the proper interleaving of operations from multiple transaction at runtime
Pessimistic
assumes transaction will conflict so we stop the problems arise in the firs t place
Optimistic
Assumes conflicts between transaction are rare, we deal with conflicts when they happen after transaction commit
Execution schedule
Serial schedules
Does not interleave the actions of different transactions
Equivalent schedules
If the effect of execution the first schedule is identical to the effect of execution the second schedule
Serializable schedules
Equivalent to any serial execution of the transactions. Different serial execution can produce different results
![]()
A Conflict between two operations
Read-write conflicts - unrepeatable reads
A transaction is not able to get the same value when reading the same objects multiple times.
Write-read conflicts - dirty reads
A transaction sees the write effects of a different transaction committing its changes.
Write-write conflicts - lost update
One transaction overwrites the uncommitted data of other concurrent transactions
conflict serializability
Conflict equivalent if they involve the same operations of the same transaction and every pair of conflicting operations is ordered in the same way in both schedules.
View serializability
Weaker notation of serializability that allows for all schedules that are conflict serializable and “blind writes”
Transaction Locks
Types of locks shared lock (s-lock), exclusive lock ( x-lock )
Shred lock - s lock
Allow multiple transactions to read the same object at the same time.
Exclusive lock - x lock
An exclusive lock allows a transaction to modify an object. This lock prevents other transactions from taking any other lock.
Two-phase locking - 2PL
2pl is a pessimistic concurrency control protocol that uses locks to determine whether a transaction is allowed to access an object in the database on the fly.
Phase - one - growing
Each transaction requests the locks that it needs from the lock manager.
Lock manager grants or denies these lock requests.
Phase - two - shrinking
Transaction enters the shrinking phase immediately after they release their first lock.
Transactions are only allowed to release locks, They are not allowed to get a new one.
Deadlock handling
Is a cycle of transactions waiting for locks to be released by each other.
Two approaches to handle deadlocks in 2pl
Approach 1 - deadlock detention
Creates a wait for graphs where transactions are nodes.
Approach 2 - deadlock prevention
Letting transaction try to acquire any lock they need and then deal with deadlocks afterwards,
Deadlock prevention 2PL stops transactions from causing deadlocks before they occur.
Lock granularities
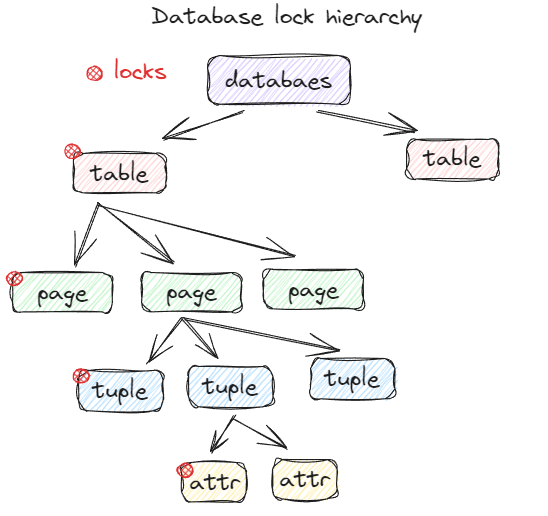
- Database level
- Table level
- Page level
- Tuple level
- Attribute level
Crash recovery
Recovery algorithms ensure ACID despite failures When a crash happens all data in memory is at risk.
Two parts
- Actions during normal transactions
- Actions after a failure.
Thins used to recover are UNDO and REDO
UNDO
Removing the effects of an incomplete
REDO
Re-applying the effects of a committed transactions
Buffer pool management polices
A Steal policy allows an uncommitted transactions to overwrite teh most recent committed value of an object in non-volatile storage.
Steal is allowed
No-steal is not allowed
A force policy updates made by a transition are reflected on non-volatile storage before the transaction is allowed to commit.
Force is required
No-force is not required
Shadow paging
Copies pages on write to maintain two separate versions of the database.
Master - contains only changes from committed transactions.
Shadow - temporary database with changes made from uncommitted transactions.
Write ahead logging
WAL records all the changes made to the database in a log file.
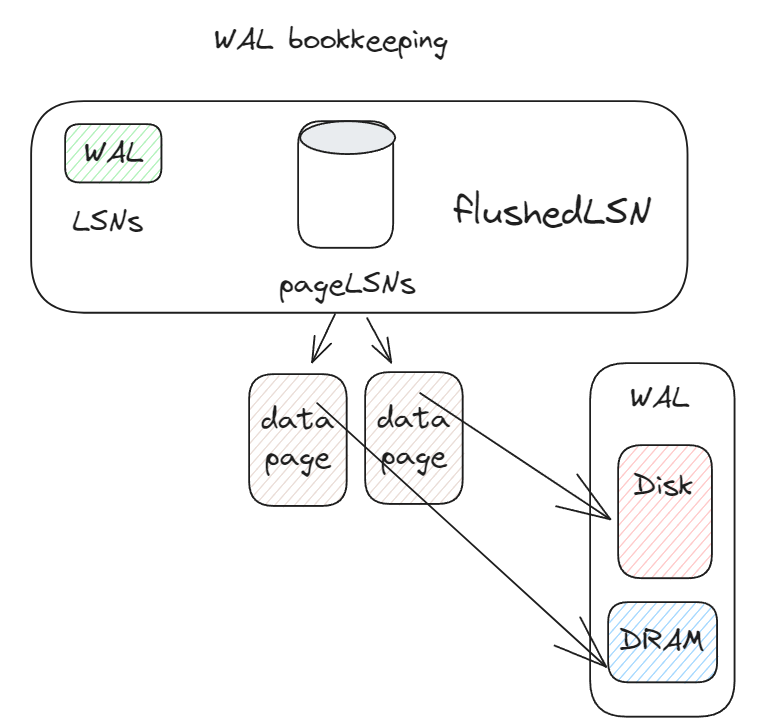
Logging schemes
Physical logging
Record the byte-level changes made to a specific location in the database
Logical logging
Records the high level operations executed by transactions , not restricted to a single page.
Physiological logging
Hybrid approach log records target a single page but does not specify data organization of the page.
Checkpoints - <CHECKPOINTS>
Periodically flushes all buffers out to disk.
Conclusion
These architecture components play a critical role. Understanding these core principles and techniques is essential for designing and maintaining modern database solutions and systems.