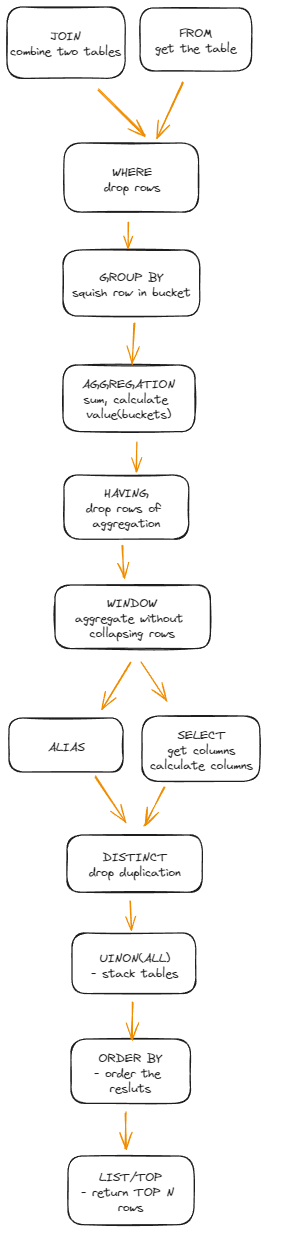
Logical order of sql
logical order of sql, How does query engine interpret the sql query.
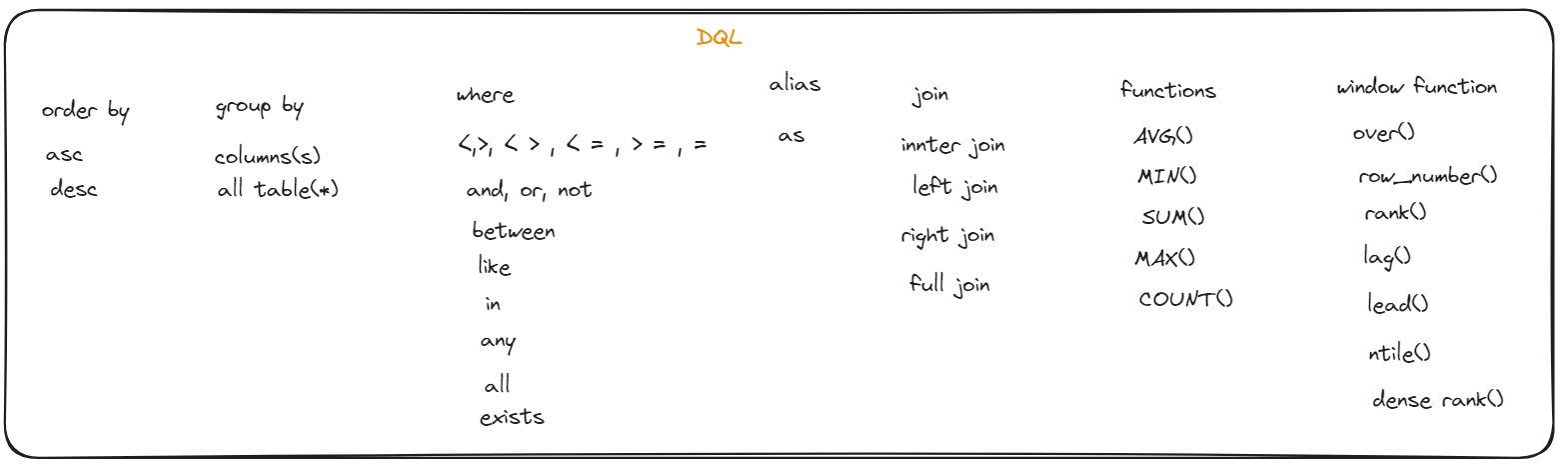
SQL commands

Using built-in functions and expression
Expressions using operators
Example :
Concatenating strings
operator : +
<string or column name> + <string or column name>
SELECT 'ab' + 'c';
Concatenating strings and NULL
SELECT
BusinessEntityID,
FirstName + ' ' + MiddleName +' ' + LastName AS "Full Name"
FROM Person.Person;
CONCAT
--1 Simple CONCAT function
SELECT CONCAT ('I ', 'love', ' writing', ' T-SQL') AS RESULT;
ISNULL and COALESCE
Two functions are available to replace NULL values
ISNULL(<value>,<replacement>)
COALESCE(<value1>,<value2>,…,<valueN>)
Concatenating other data types to strings
CAST(<value> AS <new data type>)
CONVERT(<new data type>,<value>)
Using mathematical operators
--1
SELECT
1 + 1 AS ADDITION,
10.0 / 3 AS DIVISION,
10 / 3 AS [Integer Division],
10 % 3 AS MODULO;
SELECT
OrderQty,
OrderQty * 10 AS Times10
FROM
Sales.SalesOrderDetail;
Using string functions
RTRIM and LTRIM
The RTRIM and LTRIM functions remove spaces from the right side (RTRIM) or left side (LTRIM) of a string data types
RTRIM(<string>)
LTRIM(<string>
LEFT and RIGHT
The LEFT and RIGHT functions return a specified number of characters on the left or right side of a string
LEFT(<string>,<number of characters)
RIGHT(<string>,<number of characters)
LEN and DATALENGTH
Use LEN to return the number of characters in a string.
LEN(<string>)
DATALENGTH(<string>)
CHARINDEX
Use CHARINDEX to find the numeric starting position of a search string inside another string
CHARINDEX(<search string>,<target string>[,<start location>])
SUBSTRING
Use SUBSTRING to return a portion of a string starting at a given position and for a specified number of characters
SUBSTRING(<string>,<start location>,<length>)
CHOOSE
CHOOSE is a function new with SQL Server 2012 that allows you to select a value in an array based on an index
CHOOSE ( index, val_1, val_2 [, val_n ] )
REVERSE
REVERSE returns a string in reverse order
SELECT REVERSE('!dlroW ,olleH')
UPPER and LOWER
Use UPPER and LOWER to change a string to either uppercase or lowercase
UPPER(<string>)
LOWER(<string>)
REPLACE
Use REPLACE to substitute one string value inside another string value
REPLACE(<string value>,<string to replace>,<replacement>)
Nesting functions
SELECT
EmailAddress,
SUBSTRING(EmailAddress,CHARINDEX('@',EmailAddress) + 1,50) AS DOMAIN
FROM
Production.ProductReview;
SELECT
physical_name,
RIGHT(physical_name,CHARINDEX('\',REVERSE(physical_name))-1) AS FileName
FROM
sys.database_files;
Using date and time functions
GETDATE and SYSDATETIME
Use GETDATE or SYSDATETIME to return the current date and time of the server
SELECT GETDATE(), SYSDATETIME();
DATEADD
Use DATEADD to add a number of time units to a date
DATEADD(<date part>,<number>,<date>)
DATEDIFF
The DATEDIFF function allows you to find the difference between two dates.
DATEDIFF(<datepart>,<early date>,<later date>
DATENAME and DATEPART
The DATENAME and DATEPART functions return the part of the date specified. Developers use the DATENAME and DATEPART functions to display just the year or month on reports, for example.
DATENAME(<datepart>,<date>)
DATEPART(<datepart>,<date>)
DAY, MONTH and YEAR
DAY(<date>)
MONTH(<date>)
YEAR(<date>)
CONVERT
CONVERT(<data type, usually varchar>,<date>,<style>)
FORMAT
FORMAT(value, format [, culture ]
DATEFFORMPARTS
EOMONTH
Using mathematical functions
ABS
SELECT ABS(2) AS "2", ABS(-2) AS "-2"
POWER
POWER(<number>,<power>)
SQUARE and SQRT
SELECT SQUARE(10) AS "Square of 10"
ROUND
ROUND(<number>,<length>[,<function>])
RAND
RAND returns a float value between 0 and 1
SELECT CAST(RAND() * 100 AS INT) + 1 AS "1 to 100"
Logical functions and expressions
The CASE expressions
CASE <test expression>
WHEN <comparison expression1> THEN <return value1>
WHEN <comparison expression2> THEN <return value2>
[ELSE <value3>]
END
IFF
IIF ( boolean_expression, true_value, false_value )
The TOP keyword
SELECT
TOP(<number>) [PERCENT] [WITH TIES] <col1>,
<col2>
FROM
<table1>
[ORDER BY <col1>]
Thinking about performance
Joining
Example :
INNER JOIN
SELECT <select list>
FROM <table1>
[INNER] JOIN <table2> ON <table1>.<col1> = <table2>.<col2>
OUTER JOIN
LEFT OUTER JOIN
SELECT <SELECT list>
FROM <table1>
LEFT [OUTER] JOIN <table2> ON <table1>.<col1> = <table2>.<col2>
RIGHT OUTER JOIN
SELECT <SELECT list>
FROM <table2>
RIGHT [OUTER] JOIN <table1> ON <table1>.<col1> = <table2>.<col2>
OUTER JOIN
SELECT <SELECT list>
FROM <table1>
LEFT [OUTER] JOIN <table2> ON <table1>.<col1> = <table2>.<col2>
WHERE <col2> IS NULL
FULL OUTER JOIN
SELECT <column list>
FROM <table1>
FULL [OUTER] JOIN <table2> ON <table1>.<col1> = <table2>.<col2>
CROSS JOIN
SELECT <SELECT list> FROM <table1> CROSS JOIN <table2>
SEFL JOIN
SELECT <a.col1>, <b.col1>
FROM <table1> AS a
LEFT [OUTER] JOIN <table1> AS b ON a.<col1> = b.<col2>
SUBQUERIES
Example :
Using a subquery in an IN list
SELECT <select list> FROM <table1>
WHERE <col1> IN (SELECT <col2> FROM <table2>)
Using a subquery and NOT IN
SELECT <select list> FROM <table1>
WHERE <col1> NOT IN (SELECT <col2> FROM <table2>)
A subquery in the WHERE clause can also be used to find rows that don’t match the values from another table by adding the NOT operator.
SELECT <select list> FROM <table1>
WHERE <col1> IN (SELECT <col2> FROM <table2>)
Using a subquery containing NULL with NOT IN
SELECT <select list> FROM <table1>
WHERE <col1> IN (SELECT <col2> FROM <table2> WHERE <col> IS NOT NULL)
Using EXISTS
SELECT <select list> FROM <table1>
WHERE <col1> IN (SELECT <col2> FROM <table2>)
Using CROSS APPLY and OUTER APPLY
SELECT CustomerID, AccountNumber, SalesOrderID
FROM Sales.Customer AS Cust
CROSS APPLY(SELECT SalesOrderID
FROM Sales.SalesOrderHeader AS SOH
WHERE Cust.CustomerID = SOH.CustomerID) AS A;
Using CROSS APPLY and OUTER APPLY
SELECT CustomerID, AccountNumber, SalesOrderID
FROM Sales.Customer AS Cust
OUTER APPLY(SELECT SalesOrderID
FROM Sales.SalesOrderHeader AS SOH
WHERE Cust.CustomerID = SOH.CustomerID) AS A;
UNION
SELECT <col1>, <col2>,<col3>
FROM <table1>
UNION [ALL]
SELECT <col4>,<col5>,<col6>FROM <table2>
Using EXCEPT and INTERSECT
Two query types that are similar to UNION are the EXCEPT and INTERSECT queries. Instead of combining the data, queries written with EXCEPT return rows from the left side that do not match the right side. Queries written with INTERSECT will return rows that are found in both sides
SELECT <col1>, <col2>,<col3>
FROM <table1>
EXCEPT [ALL]
SELECT <col4>,<col5>,<col6>FROM <table2
SELECT <col1>, <col2>,<col3>
FROM <table1>
INTERSECT [ALL]
SELECT <col4>,<col5>,<col6>FROM <table2
Grouping and summarizing Data
Aggregate functions
COUNT()
SUM()
AVG()
MIN()
MAX()
Group By clause
Examples :
Grouping on columns
SELECT <aggregate function>(<col1>), <col2>
FROM <table>
GROUP BY <col2>
Order by clause
SELECT <aggregate function>(<col1>),<col2>
FROM <table1>
GROUP BY <col2>
ORDER BY <col2>
Example :
WHERE clause
SELECT <aggregate function>(<col1>),<col2>
FROM <table1>
WHERE <condition>
ORDER BY <col2>
Having clause
SELECT <aggregate function1>(<col1>),<col2>
FROM <table1>
GROUP BY <col2>
HAVING <aggregate function2>(<col3>) = <value>
DISTINCT keyword
DISTINCT keyword to eliminate duplicate rows from a regular query
Windowing functions
SELECT [<col1>,][<col2>,] ROW_NUMBER() OVER(ORDER BY <col1>[,<col2>]) AS RowNum
FROM <table>;
SELECT [<col1>,][<col2>,] RANK() OVER(ORDER BY <col1>[,<col2>]) AS RankNum
FROM <table>;
SELECT [<col1>,][<col2>,] DENSE_RANK() OVER(ORDER BY <col1>[,<col2>]) AS DenseRankNum
FROM <table>;
Ranking functions
Adds a ranking for each row or divides the rows into buckets
Window functions
Allows to calculate summary values in a non-aggregated query
Accumulating aggregates
Enables the calculation of running totals
Ranking functions
ROW_NUMBER
RANK
DENSE_RANK
NTILE
Advanced CTE queries
Combine data from more than one table into one query.
CTE allows you to isolate part of query logic.
Aggregate expression in on update
;WITH <ctename> (<col1>,<col2>)
AS (SELECT <col3>,<col4) FROM <table>
SELECT <col1>,<col2>
FROM <ctename>;
Isolating aggregate query logic
Example
Correlated subqueries in the select list
SELECT <select list>,
(SELECT <aggregate function>(<col1>)
FROM <table2> WHERE <col2> = <table1>.<col3>) AS <alias name>
FROM <table1>
The merge statement
Merge statement also known as upsert
Allows you to bundle INSERT, UPDATE, DELETE operations into a single statement to perform complex operations such as syn the contents of one table with another.
Grouping sets
Allows to combine different grouping level on aggregation
Equivalent to combined with aggregate queries with UNION
SELECT <col1>,<col2>,<aggregate function>(<col3>)
FROM <table1>
WHERE <criteria>
GROUP BY GROUPING SETS (<col1>,<col2>)
CUBE and ROLLUP
Adding subtotals to aggregate queries by using CUBE or ROLLUP in the GROUP BY clause.
Example :
SELECT <col1>, <col2>, <aggregate expression>
FROM <table>
GROUP BY <CUBE or ROLLUP>(<col1>,<col2>)
Variables
Example :
Declaring and initializing a variable
DECLARE @variableName <type> = <value1>
SET @variableName = <value2>
IF
IF <condition> <statement>
IF <condition> BEGIN
<statement1>
[<statement2>]
END
WHILE
Example
WHILE <boolean expression> BEGIN
<statement1>
[<statement2>]
END
Temporary tables and table variables
Temp and table variables allow you to save data in short lived structures that you can use in scripts.
Pro :- breaks extremely complicated queries into smaller, more manageable pieces sometimes with better performance.
Example Creating local temp tables
CREATE TABLE #tableName (<col1> <data type>,<col2> <data type>)
Transactions
ACID properties guarantee the reliability of the data in a database
BEGIN TRAN|TRANSACTION
<statement 1>
<statement 2>
COMMIT [TRAN|TRANSACTION]
Atomicity
A transaction is on unit of work
Consistency
A transaction must leave the database ina consistent state.
A transaction must follow the rules like constraints, defined in the database
Isolation
A transaction cannot affect other transaction
Durability
Once a transaction has been committed, it will not be lost, even after a reboot or power outage.
Examples
Writing an explicit transaction
Rolling back a transaction
Error handling
Example :
Using try .. catch
BEGIN TRY
<statements that might cause an error>
END TRY
BEGIN CATCH
<statements to access error information and deal with the error>
END CATCH
Tables
Example :
Adding check constraints to a table
--Adding during CREATE TABLE
CREATE TABLE <table name> (<col1> <data type>,<col2> <data type>,
CONSTRAINT <constraint name> CHECK (<condition>))
--Adding during ALTER TABLE
CREATE TABLE <table name> (<col1> <data type>, <col2> <data type>)
ALTER TABLE <table name> ADD CONSTRAINT <constraint name> CHECK (<condition>)
Views
We can create a object called views that query just like tables, Views don’t store data
They are just saved query definitions.
Views provide security.
A indexed view also known as a materialized view does contain data.
Add a clustered index to view
Example :
Create a view
CREATE VIEW <view name> AS SELECT <col1>, <col2> FROM <table>
ALTER VIEW <view name> AS SELECT <col1>, <col2> FROM <table>
DROP VIEW <view name>
User defined functions
CREATE FUNCTION <scalar function Name> (<@param1> <data type1>,
<@param2> <data type2>)
RETURNS <data type> AS
BEGIN
<statements>
RETURN <value>
END
ALTER FUNCTION <scalar function Name> ([<@param1> <data type>,
<@param2> <data type>])
RETURNS <data type> AS
BEGIN
<statements>
RETURN <value>
END
DROP FUNCTION <scalar function name>
Stored procedures
Used for encapsulation of logic and security. They contain logic, update date, create other objects.etc..
Stored procedures are often used to prevent SQL injection attacks.
Example :-
CREATE PROC[EDURE] <proc name> [<@param1> <data type>,<@param2> <data type>] AS
<statements>
[RETURN <INT>]
ALTER PROC[EDURE] <proc name> [<@param1> <data type>,<@param2> <data type>] AS
<statements>
[RETURN <INT>]
EXEC <proc name> <param values>
DROP PROC[EDURE] <proc name>
Triggers
Lot of cons about them then pros in modern agile development,
Triggers are special type of stored procedures that runs when data modified
One common use of triggers is to enforce referential integrity. Or the primary key and foreign key relationships between the tables.
Triggers are the cause of performance or logical problems that are difficult to track down.