How to make processes synchronize and coordinate their actions. Multiple processes do not simultaneously access a shared resource, such as a file, granting each other temporary exclusive access
Agree on the ordering events
Eg:
Message m1 from process P was sent before or after message m2 from process Q
Synchronization and coordination are related
Process Synchronization
We make sure one process waits for another process to complete operations
Data synchronization
Two sets of data are the same
Coordination
Manage the interactions and dependencies between activities in a distributed system.
Coordination encapsulates synchronization
Issues of synchronization based on actual time
Synchronization based on relative ordering matters rather than ordering in absolute time.
Group of processes can appoint one process as a coordinator using a election algorithm
Clock synchronization
When process/nodes wants to know the time, it simply makes a call to the operating systems
If process/node A asks for the time, later process/node B asks for the time
The value that B gets will be higher than the value A got, It will certainly not be lower
Algorithms for coordination
coordinating mutual exclusion to a shared resource
Another coordination problem when we have a location problem, in distributed systems the nodes communicate between different data centers multiple availability zones.
Gossip based coordination
Clocks
Strongly related to communication between processes is the issue of how processes in distributed systems synchronize.
No notion of time, a process on different nodes has its own time.
Ways to synchronize clocks in distributed systems based on exchanging clock values along with time it took to send and receive.
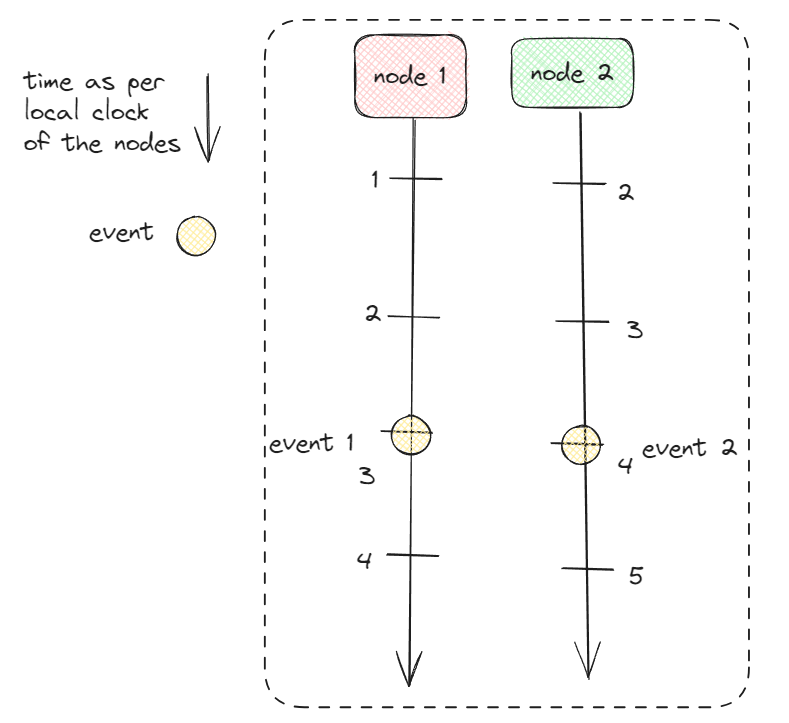
Related events at different process happening in the correct order
Logical clocks it is possible for a collection of process to reach global agreement on the correct ordering of events
Event - e
Globally unique timestamp - C(e)
When event a happened before b
C(c) < C(b)
Lamport timestamps can be extended to vector timestamps if
C(a) < C(b)
Event a casually preceded b
Clock Synchronization
Class of synchronization algorithm is that of distributed mutual exclusion
Makes sure that at most one process have access to the shared resources
It is achieved with the help of a coordinator that keeps track of whose turn it is.
problem with clocks
Synchronization between nodes only achieved with help of one nodes which acts as a coordinator
Time, Clocks and the Ordering of Events in a Distributed System - Microsoft Research
Physical clocks
Most computers have a special battery-backed up CMOS RAM so that the date and time need
not be entered on subsequent boots. At every clock tick, the interrupt service
procedure adds one to the time stored in memory. In this way, the (software)
The clock is kept up to date.
Logical clocks
usually matters is not that all processes agree on exactly what time it is, but rather that they agree on the order in which events occur.
Lamport’s logical clocks
Relationship
Happens-before
A → B ( event a happens before event b occurs )
Step 1
If a and b are events in the same process,
A occurs before b
Than
A → b is true
Step 2
If a is the event of a message being sent by one process,
And b is the event of the message being received by another process
Then
A → b is also true
A message being received by another process,
Then a → b is also true
Since it takes a finite, nonzero amount of time to arrive.
Happens-before is a transitive relation
If a → b and b → c, then a → c
If two events, x and y, happens in different process that do not exchange message,
Then
X → y is not true
But
Neither y → x
These events are said to be **concurrent** ( nothing can be said which event happened before )
A way of measuring a notion of time such that for every event
A we can assign it a time value C(a) on which all processes agree.
These time values must have the property that if
* a → b
Than
C(a) < C(b)
If a and b are two events within the same node and a occurs before b then C(a) < C(b)
Similarly if a is the sending of a message by one process dn b is the reception of that message by another process,
Then
C(a) and C(b) must be assigned in such a way that everyone agrees on the values of C(a) and C(b)
With
C(a) < C(b)
The clock time C always must go forward
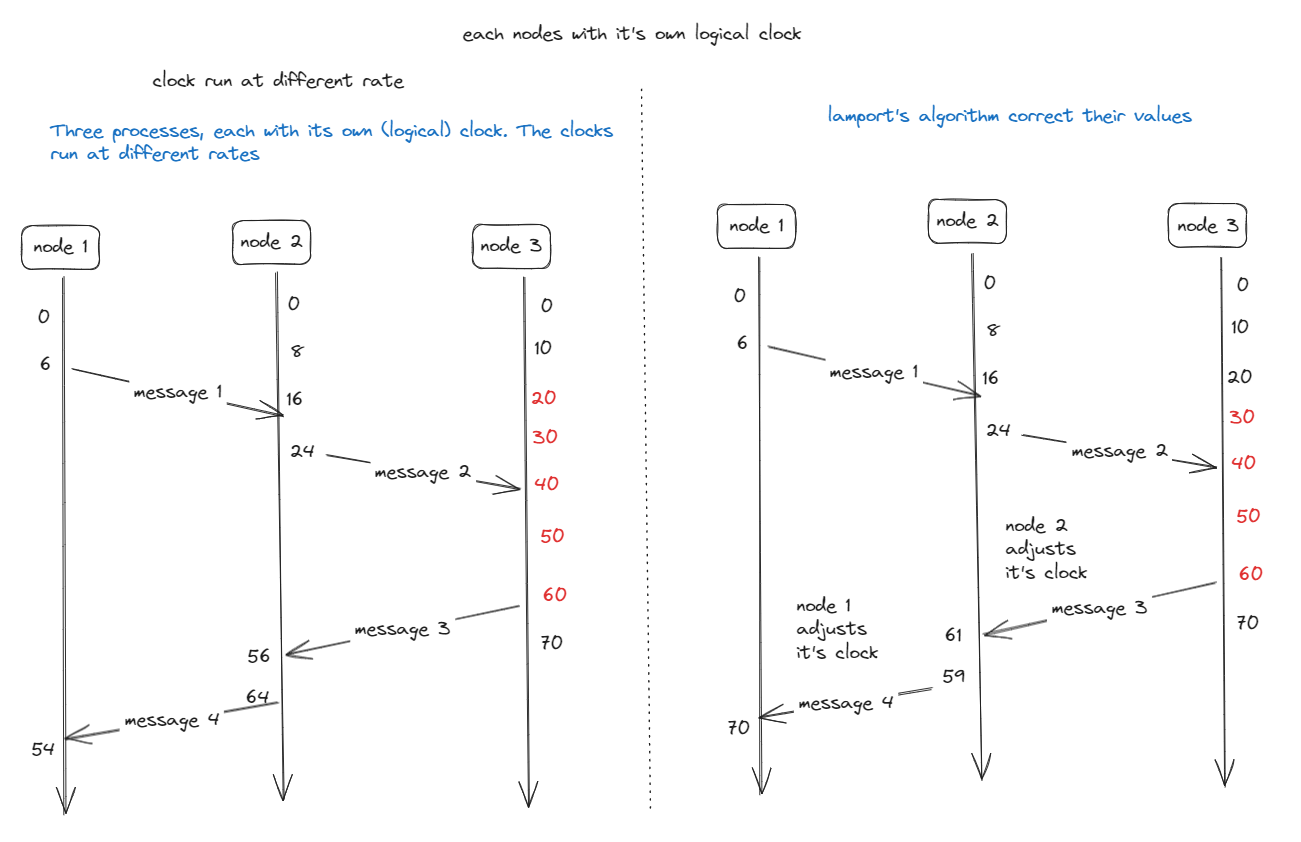
Lamport Algorithm
Step 1
Before executing an event node-i increments
Counter_i = counter_i + 1
Step 2
When node p_i ends a message m to node_j
It’s sets m’s timestamp
time_stamp(m) = counter_i
After having executed the previous step
Step 3
Once the message m, node_p_j adjusts it’s own local counter as
Counter_j = Max(counter_j, time_stamp(m))
After that it executes the first step and delivers the message to the application
Example :
Totally ordered multicasting
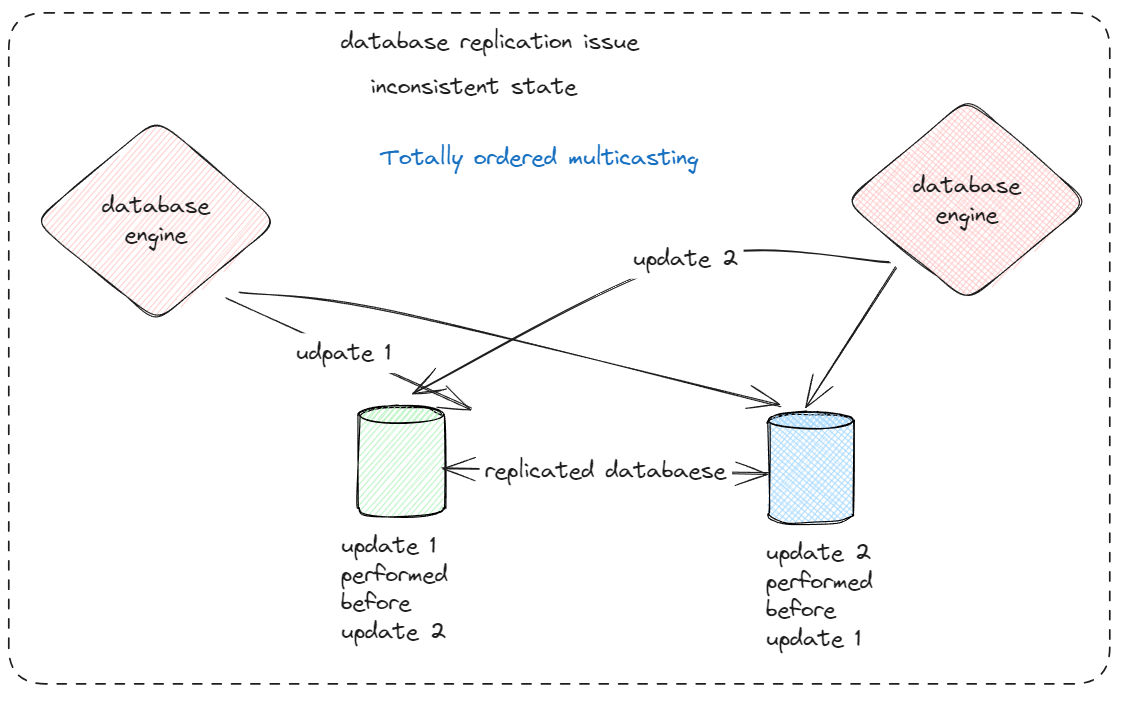
situations in which the database has been replicated across several zones.
The problem that we are faced with is that the two update operations
should have been performed in the same order at each copy.
which order is followed is not essential from a consistency perspective.
In general, situations such as these require a totally ordered multicast
A multicast operation by which all messages are delivered in the same order to each receiver
Group of nodes multicasting message to each other
Each message is alway time stamped with the current time of it’s sender
When a message is multicasted, sender sent the message, receiver received in the order they were sent and no message is lost
When node receives a message, it’s put into a local queue
Ordered according to it’s timestamp
The receiver multicasts an ack to the other nodes
Total ordered multicasting is important for replicated services
Where the replicas are kept consistent by letting them execute the same operations in the same order everywhere.
Replicas essentially follow the same transitions in the same finite state machine
It is known as state machine replication
Vector clocks
Lamport logical clos has a problem where in a distributed system are totally ordered with the property that
If a happened before b
Then
, a will also be positioned in that ordering before b
That is C(a) < C(b)
There is not relationship between two events a and b by merely comparing their time values C(a) and C(b)
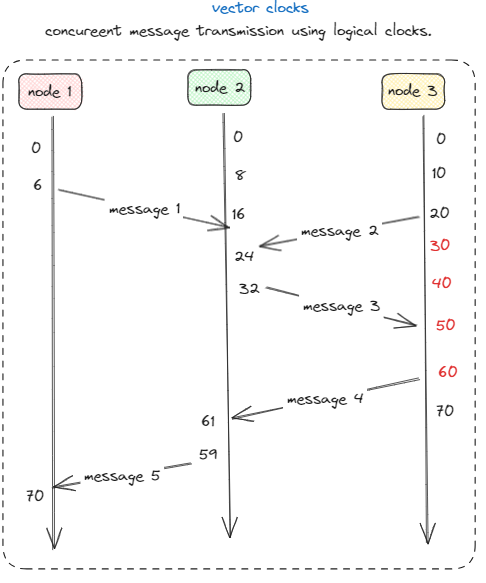
Message _i == message _1
And message _j = message _3
In the node 2 the values message _3 was sent after the receiving message _1
Sending message _3 depends on message _1
Time _recieved(message _1) < time _sent(message _2)
Lamport clocks do not capture casualty, Casualty is captured by means of vector clocks
To track casualty assign each event a unique name combination of node _id and locally incrementing counter
Node _k is the kth event that happened at nodes N
Keeping track of casual histories
Eg:
Two local events happened at node p
Then
The casual history H(node _2) of event node _2 is {node _1,node _2 }
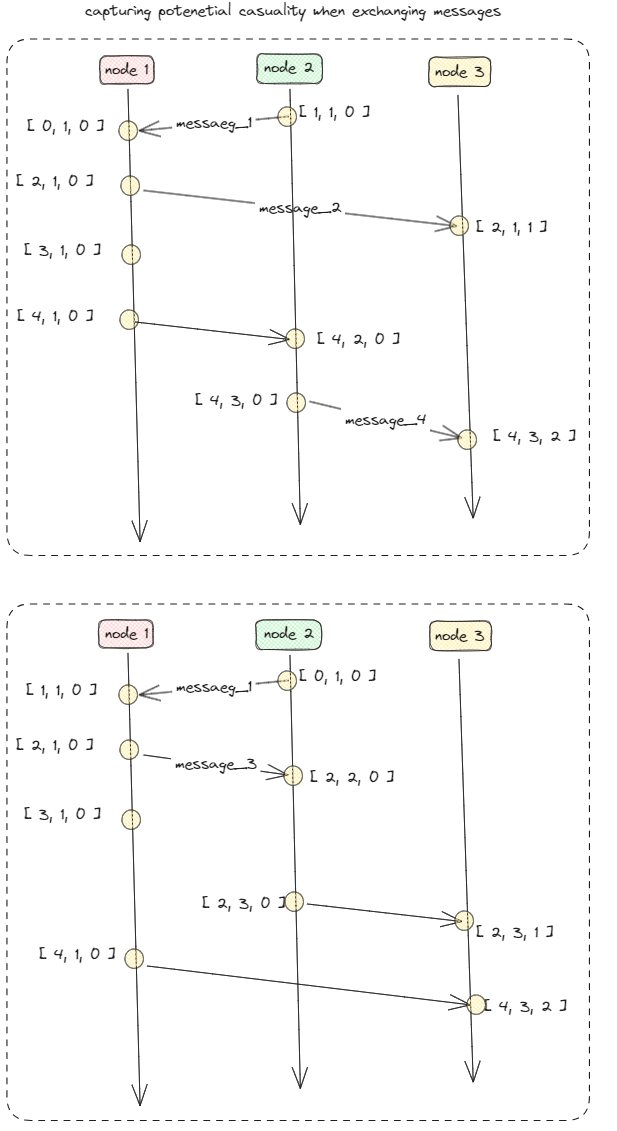
time _stamp(message _2) < time _stamp(message _4) message _2 may casually precede message _4
time _stamp(message _2) > time _stamp(message _4) message _2 and message _4 may conflict
Mutual exclusion
Fundamental to distributed systems is the concurrency and collaboration
among multiple nodes/processes.
To prevent that such concurrent accesses corrupt the resource, or make it inconsistent
distributed algorithms for mutual exclusion
Example :
Simple locking with zookeeper
Election algorithm ( leader election )
In distributed systems one node acts as coordinator to perform some special role..
election algorithms attempt to locate the node/process with the highest identifier and designate it as coordinator
we also assume that every node/process knows the identifier of every other process
Each node/process has complete knowledge of the process group in which a coordinator must be elected.
The goal of an election algorithm is to ensure that when an election
starts, it concludes with all processes agreeing on whom the new coordinator
is to be.
A coordinator is not fixed, we need election algorithm to decide who is going to be the coordinator in the cluster
A coordinator can crash so in this case we need a algorithm to figure out who will be the next coordinator
Gossip based coordination is being able to select another peer randomly from an entire overly
Location system
large distributed systems that are dispersed across a wide-area network, it is often necessary to take proximity into account
location-based techniques to coordinate the placement of processes and their communication.
GPS global position system
Consistency and replication
Important issue in distributed systems is replication of data ,Data replication enhances reliability or improve performance
Two reasons for replicating data:
Improve the reliability of a distributed system and improving performance
Replication introduces a consistency problem.
Problem :
Whenever a replica is updated, that replica becomes different from the others. To keep replicas consistent, we need to propagate updates in such a way that temporary inconsistencies are not noticed.
Doing replication degrades performance. Especially in large-scale distributed systems
The solution is to relax consistency, with different consistency models
Goal :
Set bounds to numerical deviation between replicas, saleness deviation and deviation in the ordering of operations
Numerical deviation refers to the value by which replicas may be different; this type of deviation is highly application dependent.
Replicas consistent
When on copy is updated we need to ensure that the other copies are updated
If not, replicas will no longer be the same.
Data replication is useful and it is related to scalability
Consistency
Consistent ordering of operations has since long formed the basis for many consistency models.
Sequential consistency essentially provides the semantics that programmers expect in concurrent programming.
All writes operations are seen by everyone in the same order causal consistency
Weaker consistency models consider a series of read and write operations.
They assume that each series is appropriately “bracketed” by accompanying operations on synchronization variables such as locks.
Consistency models
Multiple process simultaneously access shared data
Consistency model for shared data is hard to implement efficiently in large-scale distributed systems
A easier consistency model is client centric models
Consistency implementation
Concentrating on managing replica
Consistent replicas
Sequential consistency
write_i(X)a the node_1 writes value a to data item X
read_I(x)b, node_1 reads x and is returned the value b
Initial value of data time is NIL
When we do not know which node have access data we do omit the index symbols from write and read
Behavior of two processes operating on the same data time
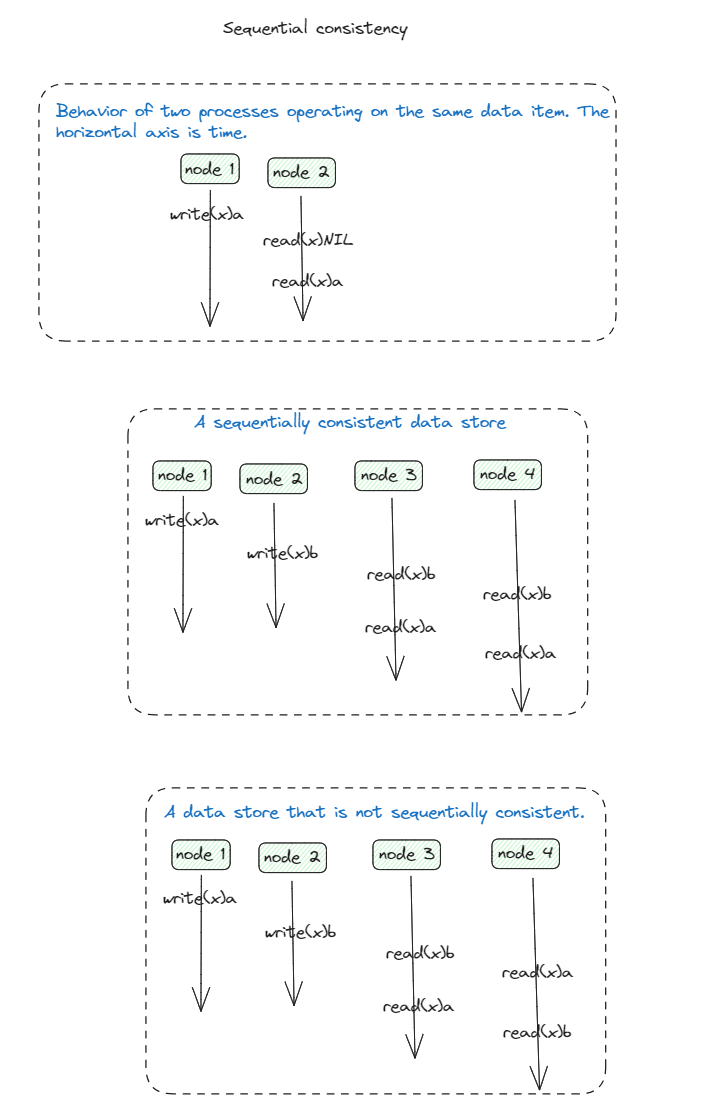
Diagram explained :
Node_1 writes data item x, modifying its value to a.
The operation write_1(x)a is first performed on a copy of data store at local node_1
Only then is propagated to the other local copies
The result of any execution is the same as if the (read and write) operations
by all processes on the data store were executed in some sequential order
and the operations of each individual process appear in this sequence in
the order specified by its program.
Causal consistency
if two processes spontaneously and simultaneously write two different data items, these are not causally related.
Operations that are not causally related are said to be concurrent.
Writes that are potentially causally related must be seen by all processes
in the same order. Concurrent writes may be seen in a different order on
different machines.
- Violation of causally consistent store
- A correct sequence of events in a causally consistent store.
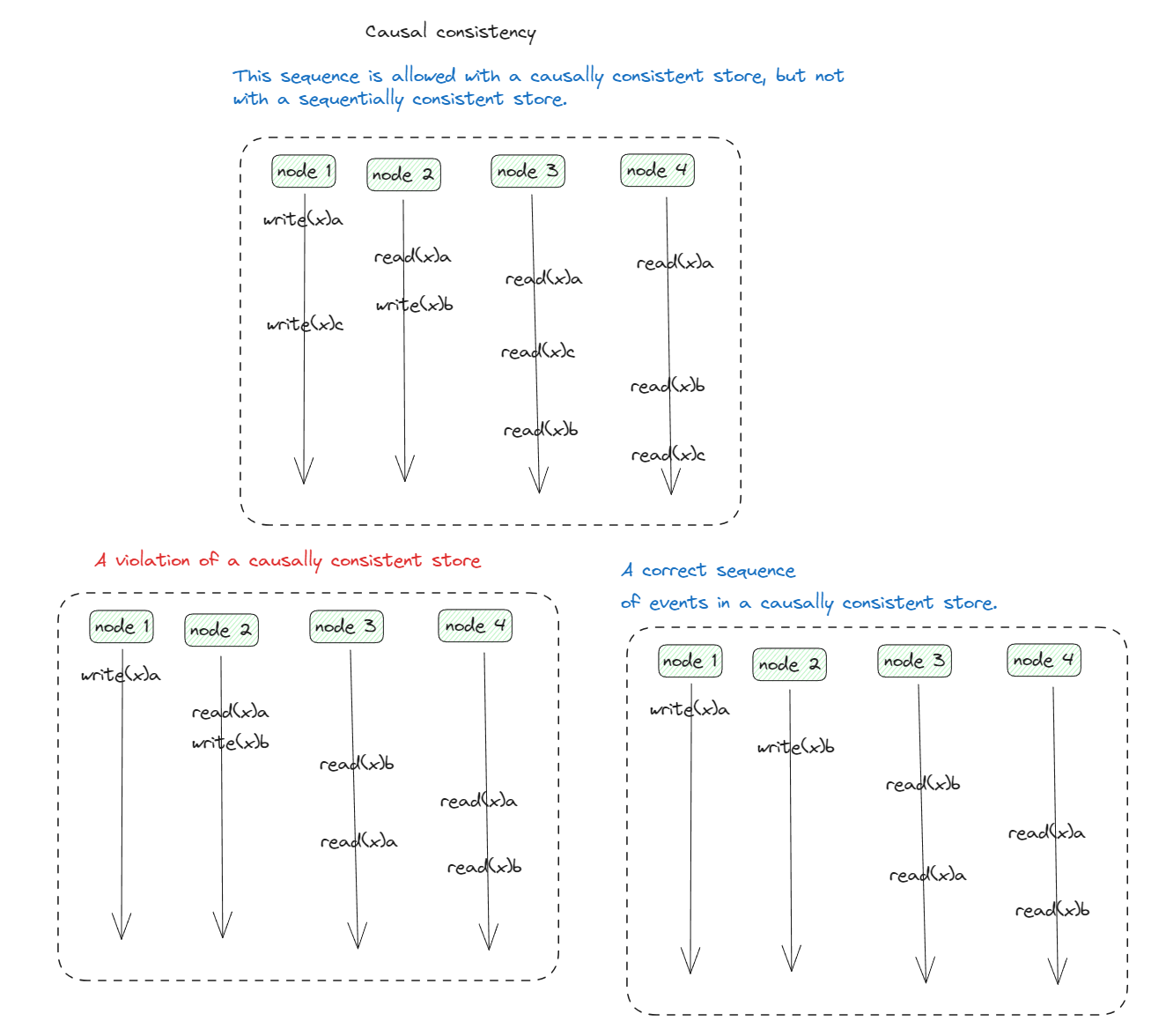
Violation of causally consistent store
write_2(x)b depending on write_1(x)a, writing value b into x may be a result of computation involving the previously read value by read_2(x)a
The two wires are causally related
All process must see them in the same order
A correct sequence of events in a causally consistent store
Reads has been removed
So write_1(X)a and write_2(x)b are now concurrent writes.
A causally consistent store does not require concurrent writes to be globally ordered
Eventual Consistency
Most nodes hardly ever perform update operations, They mostly read data from the database
The question then is how fast updates should be made available to only-reading nodes?
There are normally no write-write conflicts to resolve
Conflicts resulting from two operations that both want to perform an update on the same data ( write-write conflicts) never occur.
The only situation that needs to be handled are read-write conflicts, one process intends to update a data item while another is concurrently attempting to read that item.
Acceptable to propagate an update in a lazy fashion, i..e reading nodes will see an update only after some time has passed since the update took place.
Example :
In distributed databases replication that tolerant a relatively high degree of inconsistency.
They have in common that if no updates take place for a long time.
All replicas will gradually become consistent.
This form of consistency is called eventual consistency.
That have this property laking write-write conflicts
Eventual consistency requires only that updates are guaranteed to propagate to all replicas.
Write-write conflicts are often relatively easy to solve when assuming that only a small group of processes can perform updates.
Cheap to implement
Write-write conflicts hardly occur, when they do we need coordinate their actions by making use of mutual-exclusion
Which is a performance bottleneck.
Coordination or weakening consistency requirements
Approaches 1 - Strong eventual consistency
if there are conflicting updates, that nevertheless the replicas where those
updates have taken place, are in the same state.
Approaches 2 - CRDT ( conflict-free replicated data type)
CRDT is a data type that can be replicated at many different
sites, yet most importantly, can be updated in a concurrent fashion without
further coordination.
Monotonic Reads
monotonic-read consistency
If a process reads the value of a data item x, any successive read operation
on x by that process will always return that same value or a more recent
value
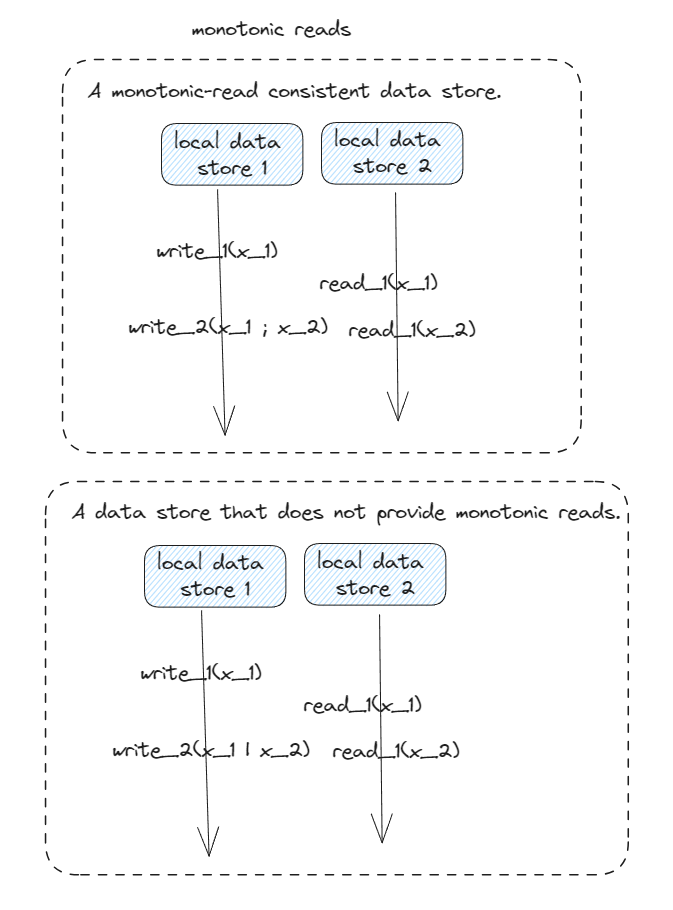
Explaining figure :
L = local data stores,
Local_data_store_1
local_data_store_2
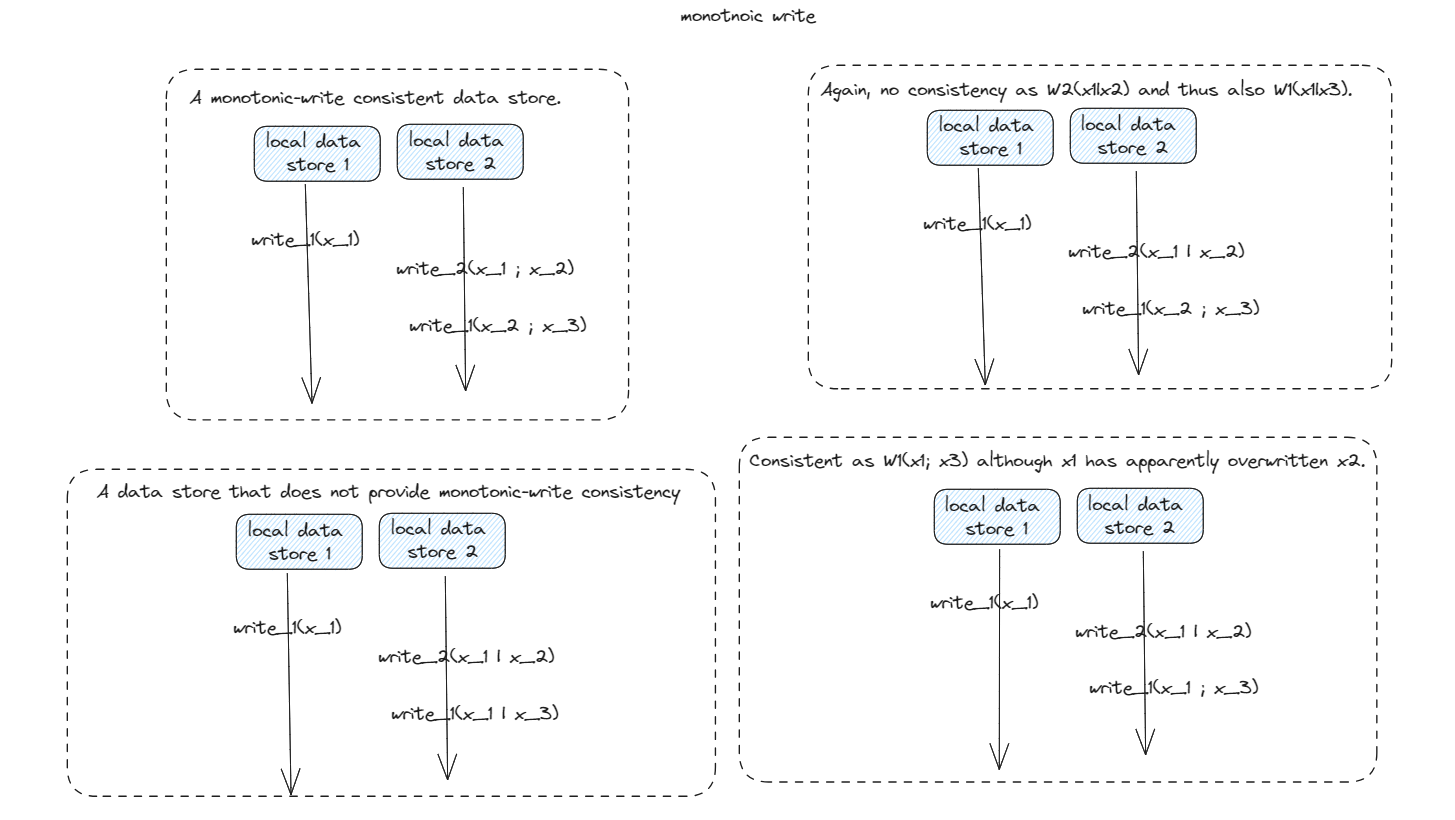
Monotonic writes
monotonic-write consistent store
A write operation by a process on a data item x is completed before any
successive write operation on x by the same process
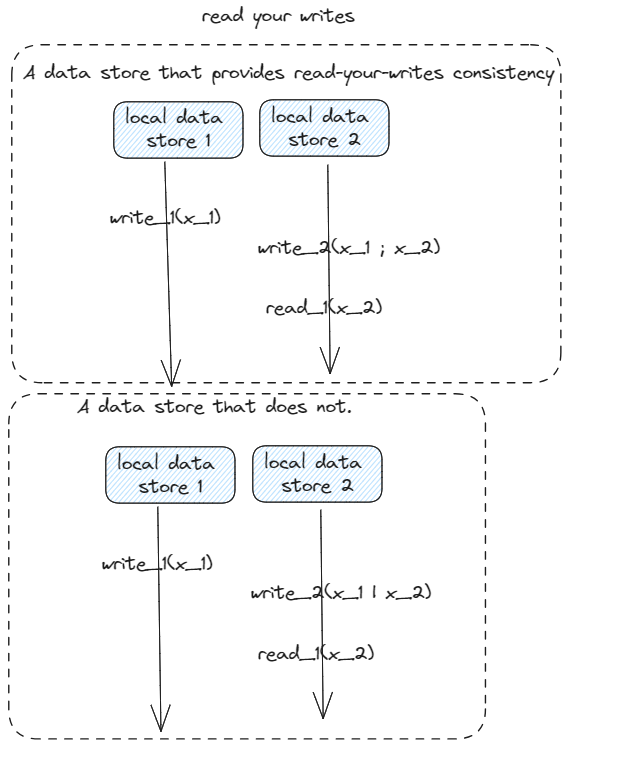
Read your writes
read-your-writes consistency
The effect of a write operation by a process on data item x will always be
seen by a successive read operation on x by the same process.
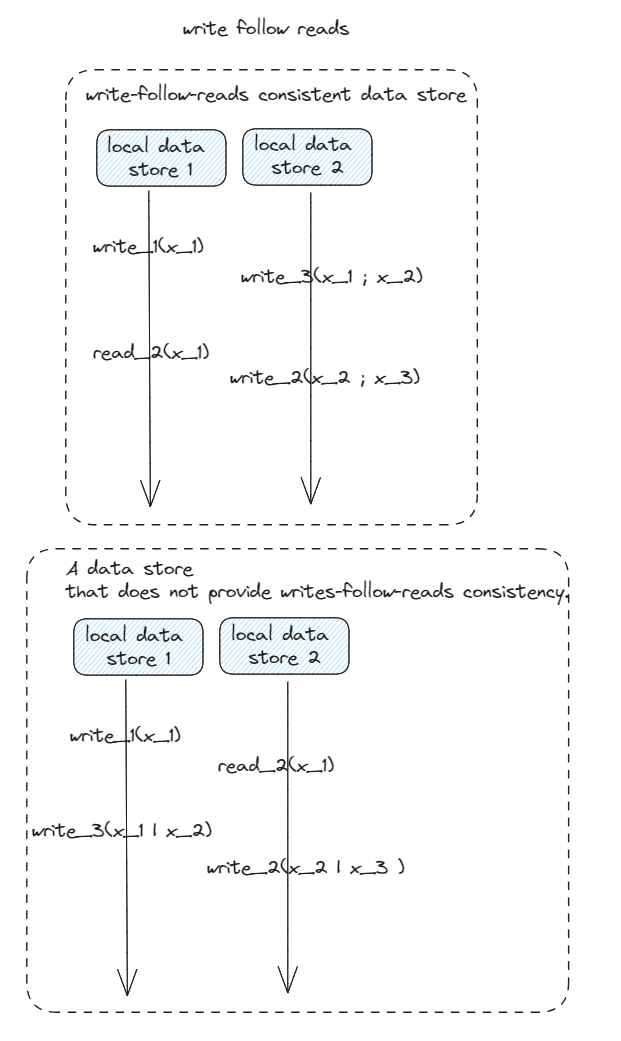
Write follow reads
writes-follow-reads consistency
A write operation by a process on a data item x following a previous read
operation on x by the same process is guaranteed to take place on the same
or a more recent value of x that was read.
Fault tolerance
One of the characteristic feature of distributed systems that distinguishes them from single-machine system is the notion of partial failures
Distributed systems expected to be failed
process/node resilience through process/nodes groups. Multiple identical processes cooperate, providing the appearance of a single logical process..
A specifically difficult point in process groups is reaching consensus among the group members on which a client-requested operation is to perform.
We pay attention to reliable group communication and notably atomic multicasting.
Distributed commit protocols by which a group of processes is conducted to either jointly commit their local work. Or collectively abort and return to a previous system state.
To recover from a failure, In particular, we consider when and how the state of a distributed system should be saved to allow recovery to that state later on.
The key technique for handling failures is redundancy
Basic concepts
How to tolerate faults being fault torrent is related to dependable systems
Availability
Defined as the property that a system is ready to be used immediately.
Highly available system is one that will most likely be working at a given instant in time.
Reliability
Refers to the property that a system can run continuously without failure.
In contrast to availability, reliability is defined in terms of a time interval
If a system goes down on average for one, seemingly random
millisecond every hour, it has an availability of more than 99.9999 percent
Safety
Refers to the situation that when a system temporarily fails to operate correctly
Maintainability
refers to how easily a failed system can be repaired, a highly maintainable system may also show a high degree of availability.
fault tolerance
meaning that a system can provide its services even in the presence of faults.
Transient faults
occur once and then disappear.
Intermittent fault
occurs, then vanishes of its own accord, then reap-pears, and so on.
Permanent fault
is one that continues to exist until the faulty compo-nent is replaced
Failure model
Crash failure occurs when a process simply halts
Omission failure occurs when a process does not respond to incoming requests
Timing failure occurs when process responds too soon or too late to a request
Response failure occurs occurs when responding to an incoming request but in the wrong way
Very difficult failure to handle is byzantine failures, also known as arbitrary failures
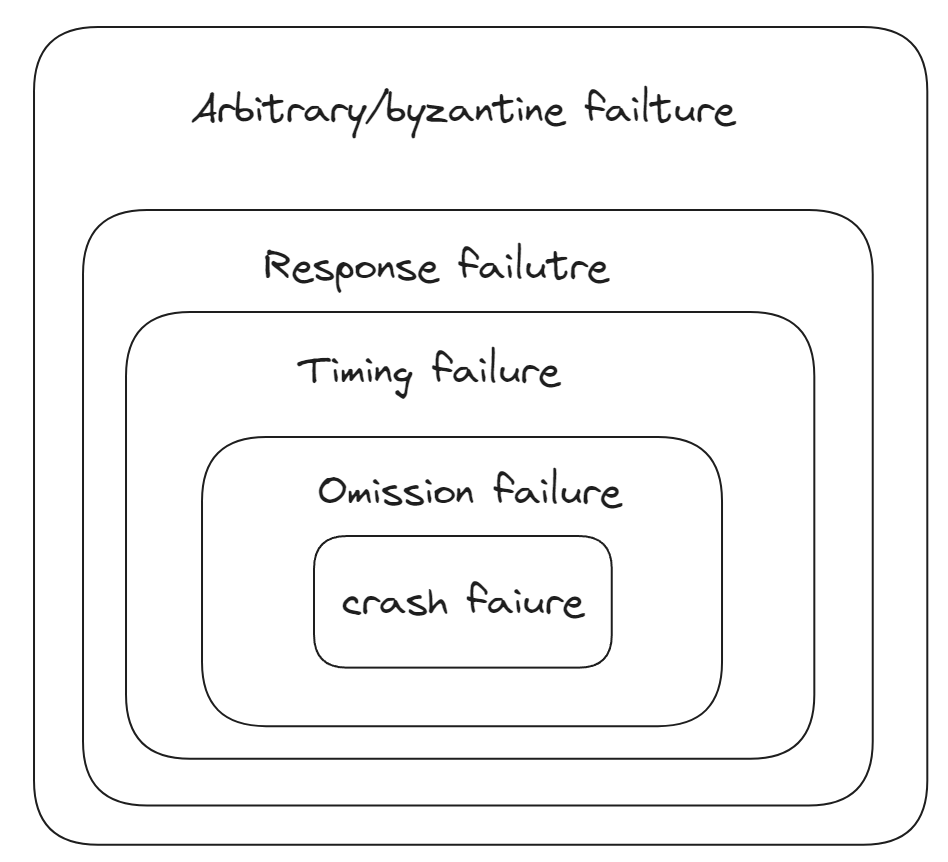
| Type of Failure | Description of Server's Behavior |
|---|---|
| Crash failure | Halts, but is working correctly until it halts |
| Omission failure | Fails to respond to incoming requests |
| Receive omission | Fails to receive incoming messages |
| Send omission | Fails to send messages |
| Timing failure | Response lies outside a specified time interval |
| Response failure | Response is incorrect |
| Value failure | The value of the response is wrong |
| State-transition failure | Deviates from the correct flow of control |
| Arbitrary failure | May produce arbitrary responses at arbitrary times |
A characteristic feature of distributed system that distinguishes them from single-machine systems is the notion of
Halting failures can be classified as follows
Fail-stop failures
Refer to crash failures that can be reliably detected.
Fail-noisy failures
Like fail-stop failures, expect that P will only eventually come to the correct conclusion that Q has crashed.
Fail-silent failures
we assume that communication links are non-faulty, but that process P cannot distinguish crash failures from omission failures.
Fail-safe Failures
Cover the case of dealing with arbitrary failures by process Q, yet these failures are benign: they cannot do any harm.
Fail-Arbitrary Failures
Q may fail in any possible way; failures may be unobservable in addition to being harmful to the otherwise correct behavior of other processes.
partial failures
Part of the system is failing while the remaining part continues to operate correctly.
A goal in distributed systems design is to construct the systems in such a way that it can automatically recover from partial failures
Distributed systems expected to be fault tolerant
Process resilience through process groups
Multiple identical processes co-operate providing the appearance of a single logical process, in case of one failure the client will never notice.
A difficult thing to do in process groups is to reach consensus among the group members on which a client-requested operation is to perform
Raft modern and easy to understand consensus algorithm.
Recognized as being faulty
Fault tolerance and reliable communication are strongly related
Reliable group communication with atomic multicasting, makes developing fault-tolerant solution much easier
Distributed commit protocols
Groups of process is conducted to either jointly commit theri local work, Collectively abort and return to a previous system state.
Distributed commit is often established by a coordinator
One-phase commit protocol
Coordinator tells all other process/nodes that are also involved
The common one being the two-phase commit protocol
Drawback of 2PC :
Cannot generally efficiently handle the failure of the coordinator
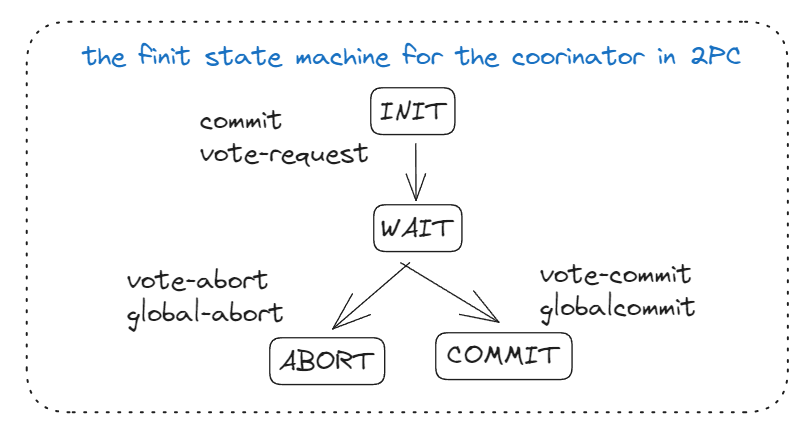
2PC protocol -steps
STEP 2
The coordinator sends a VOTE-REQUEST message to all participants.
STEP 2
When a participant receives a VOTE-REQUEST message,
Returns a VOTE-COMMIT message to locally commit it’s part of the transaction or else VOTE-ABORT message
STEP 3
Coordinator collects all votes from the participants
If all participants have voted to commit the transaction
Coordinator will send a GLOBAL-COMMIT message to all participants.
If one participants voted to abort the transition
Coordinator will also decide to abort the transaction and multicast a GLOBAL-ABORT message.
STEP 4
Each participant that voted for a commit waits for the final reaction by the coordinator.
If a participant receives a GLOBAL-COMMIT message.
It locally commits the transaction.
When receiving a GLOBAL-COMMIT message, the transaction is locally aborted as well.
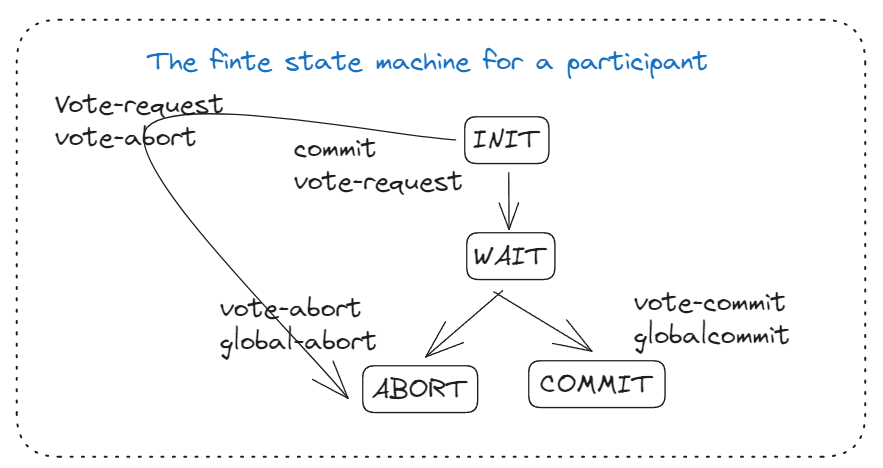
Atomic multicast
To achieve reliable multicasting in the presence of failures
A guarantee that a message is delivered to either all group member or to non this is known as the Atomic multicast problem
Synchrony
Reliable multicast in the presence of failure can be accurately defined in terms of process groups and changes to group membership.
A model in which the distributed system consists of message-handling components
A received message is locally buffered in the component until it can be delivered to the application.
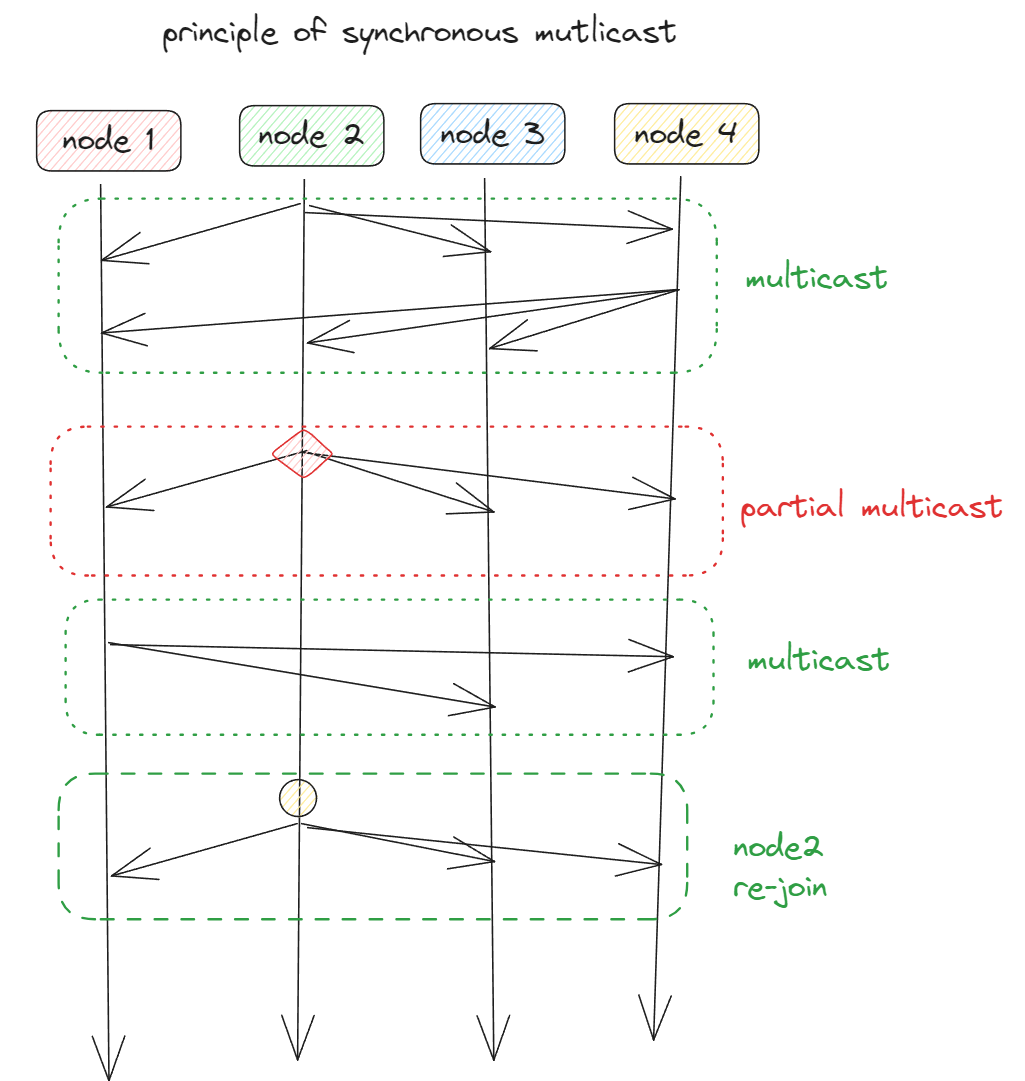
Message ordering
Unordered multicast
FIFO-ordered multicast
Causally ordered multicast
Totally ordered multicast
Reliable, unordered multicast is a synchronous multicast in which no guarantees are given concerning the order in which received messages are delivered by different process/nodes
Note:
Reliable multicasting all-or-nothing property for delivering messages.
| Step/event order | Process P1 | Process P2 | Process P3 |
|---|---|---|---|
| 1 | sends m1 | receives m1 | receives m2 |
| 2 | sends m2 | receives m2 | receives m1 |
Reliable FIFO-ordered multicast
Message handling is forced to deliver incoming messages from the same node/process in the same order as they have been sent.
| Step/event order | Process P1 | Process P2 | Process P3 | Process P4 |
|---|---|---|---|---|
| 1 | sends m1 | receives m1 | receives m3 | sends m3 |
| 2 | sends m2 | receives m3 | receives m1 | sends m4 |
| 3 | receives m2 | receives m2 | ||
| 4 | receives m4 | receives m4 |
Totally ordered delivery
Regardless of whether message delivery is unordered, FIFO ordered, or casually ordered
It is required additionally that when message are delivered
Delivered in same order to all group members.
Atomic multicasting
Synchronous reliable multicasting offering totally ordered delivery of messages.
All-or-nothing property
A message should be delivered to all members or none of them do.
| Multicast Type | Message Ordering | TO Delivery? |
|---|---|---|
| Basic message ordering | None | No |
| Reliable multicast | None | No |
| FIFO multicast | FIFO-ordered delivery | No |
| Causal multicast | Causal-ordered delivery | No |
| Atomic multicast | None | Yes |
| FIFO atomic multicast | FIFO-ordered delivery | Yes |
| Causal atomic multicast | Causal-ordered delivery | Yes |
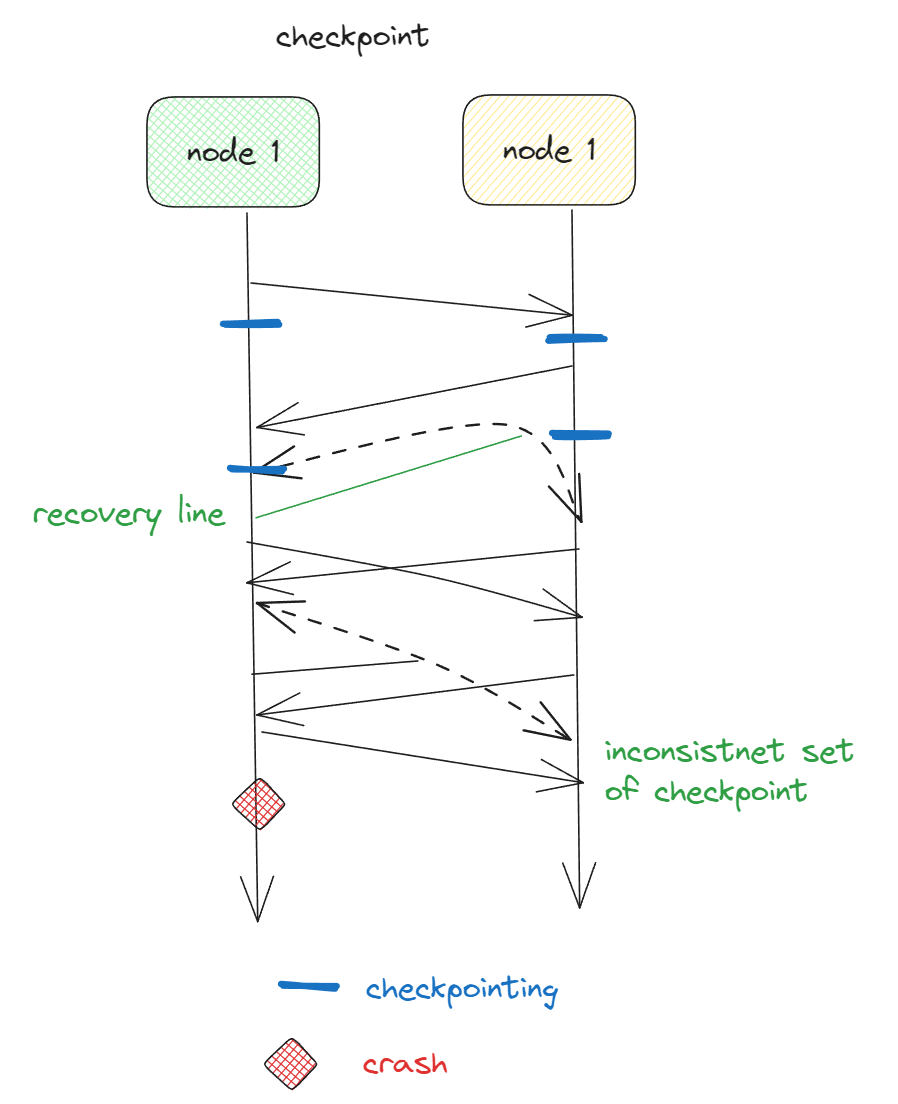
Recovery
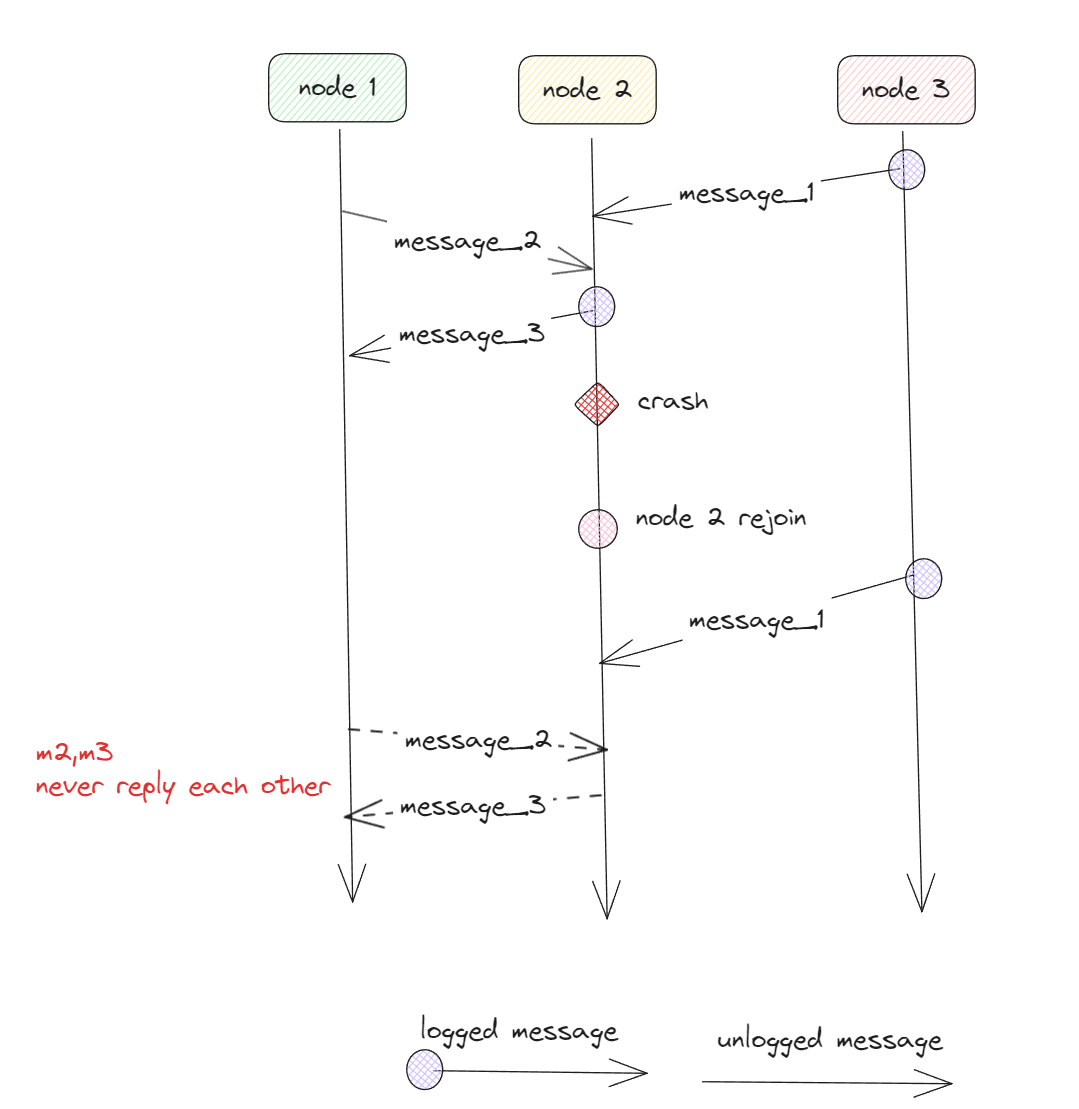
Once a failure has occurred it is essential that the process where the failure happened can recover to a correct state.
Distributed systems state can be recorded and recovered through checkpointing and message logging
Recovery in fault-tolerant systems is invariably achieved by checkpointing the state of the systems on a regular basis
Checkpointing is completely distributed but every expensive operation, To improve the performance a lot of systems do message logging.
By logging the communication between nodes/processes it is possible to replay the execution of the systems after a crash has occurred.
Backward recovery Main issue is to bring the system from it’s present erroneous state back into a previously correct state.
To restore such a recorded state when system failed, each time the system present state is recorded a checkpoint is made
Another form of error recovery is forward recovery in this case, when the system has entered an erroneous state, instead of moving back to a previous state.
Problem with forward recovery is that it has to be known in advance which error might occur.
message logging orphan process