Spanner
Was not easy to read this research paper, i made some notes on my findings,
Easy to use programming model
- Automatically shards data across nodes for scalability
- Decouples storage from compute for fast load balancing
- Replicates using paxos for consistency and high availability
- Use two-phase commit to provide transactional consistency across shards
- Enables read-only transactions with MVCC and TruTime for higher scalability
Database features
Sql query language
ACID
Schematied tables
Semi-relational data model
Motivation
Google's motivation to create a plant level distributed database system ( which never have been done before )
- Storage for google’s ad data ( F1 )
- To replace the replicated sharded MYSQL database which was used.
Database Design
Snapshot isolation ( SI )
Multi-version concurrency control
Multi-version concurrency control
- Writers do not block readers
- Readers do not block writers
Read only transactions can read a consistent snapshot without acquiring locks
Use timestamps to determine visibility
MVCC naturally support snapshot isolation ( SI )
Multi-version without garbage collection allows the DBMS to support time-travel queries
Snapshot isolation
When a transaction starts, it sees a consistent snapshot of the database that existed when that transaction started.
Write skew anomaly can happen in SI
Design goals
External consistency / linearizability
Distributed database
Concurrency control
Replication
Time ( NTP, marzullo algorithm )
Features
Lock free distributed read transactions
Property
External consistency of distributed transactions
commit order of transactions is the same as the order in which you actually appear in which users actually see.
transactions executed with respect to global wall clock time and spanner is
Implementation ( Correctness and performance )
Integration of concurrency control
Replication
2pc
New technology
True Time ( interval-based global time )
106 nodes
1024 data
Consistency properties :
Serialiable transaction isolation ( two-phase locking for serializability )
Lineraizable reads and writes
Atomic commit of transaction across shards ( two-phase commit atomicity )
No lock read only transaction
State machine replication ( paxos ) within a shard
Consistent snapshots
What is spanner?
Spanner is a google
- scalable
- Multi-version
- Globally distributed
- Synchronously-replicated database
What did spanner do especially?
First distributed database systems to support
- Global scale
- Support external-consistent distributed transactions
Research Paper
- How it is structured
- It’s features set
- Design decision
- A novel time API that exposes clock uncertainty
The api and it’s implementations are critical to supporting external consistency
Powerful features
- Non-blocking reads in the past
- Lock-free read-only transactions
- Atomic schema changes across all spanners
What is the motivation for spanner?
- Google used it for there ad data
At high level abstraction? What does this spanner do?
It is a database that shards data across many sets of Paxos state machines in data- centers spread all over the world.
Replication is used for global availability and geographic locality;
clients automatically failover between replicas.
spanner automati-cally reshards data across machines as the amount of data or the number of servers changes
it automatically migrates data across machines (even across datacenters)
to balance load and in response to failures.
Spanner is designed to scale up to millions of machines across hundreds of data centers and trillions of database rows.
What can an application use spanner for?
can use Spanner for high availability even in the face of wide-area natural disaster
By replicating their data within or even across continents.
Customers using google spanner
F1 was the first customer
a rewrite of Google’s advertising backend
F1 uses 5 replicas spread across the united states
Most applications choose lower latency over high availability.
What is the main focus of spanners?
Spanner's main focus was Cross-datacenter replicated data. But they also implemented important database features on top of distributed-system infrastructure.
Even google has bigtable they consistently received complaints from users that bigtable can be difficult to use for some kinds of applications.
Many applications at Google have chosen to use the megastore semi relational data model and support for synchronous replication.
Spanner has evolved from a bigtable-like versioned key-value store into a temporal multi-version database.
Spanner supports general transaction, sql query language.
Feature of spanner
- Replication configuration for data can be dynamically controlled at fine grain by application
- Constraints to control which datacenters contain which data
- How far data is from it’s users ( to control read latency )
- How far replicas are from each other ( to control write latency )
- How many replicas are maintained ( to control durability, availability and read performance )
Data can be dynamically and transparently moved between datacenters by the system to balance resource usage accorse datacenters.
Distributed Database features
- Provides external consistents Reads and writes
- Globally-consistent reads across the database at a timestamp
Consistent backups
Consistent mapreduce executions
Atomic schema updates
All at global scale even in process of ongoing transaction
Implementation
Directory abstraction
Which is used to manage replication and locality
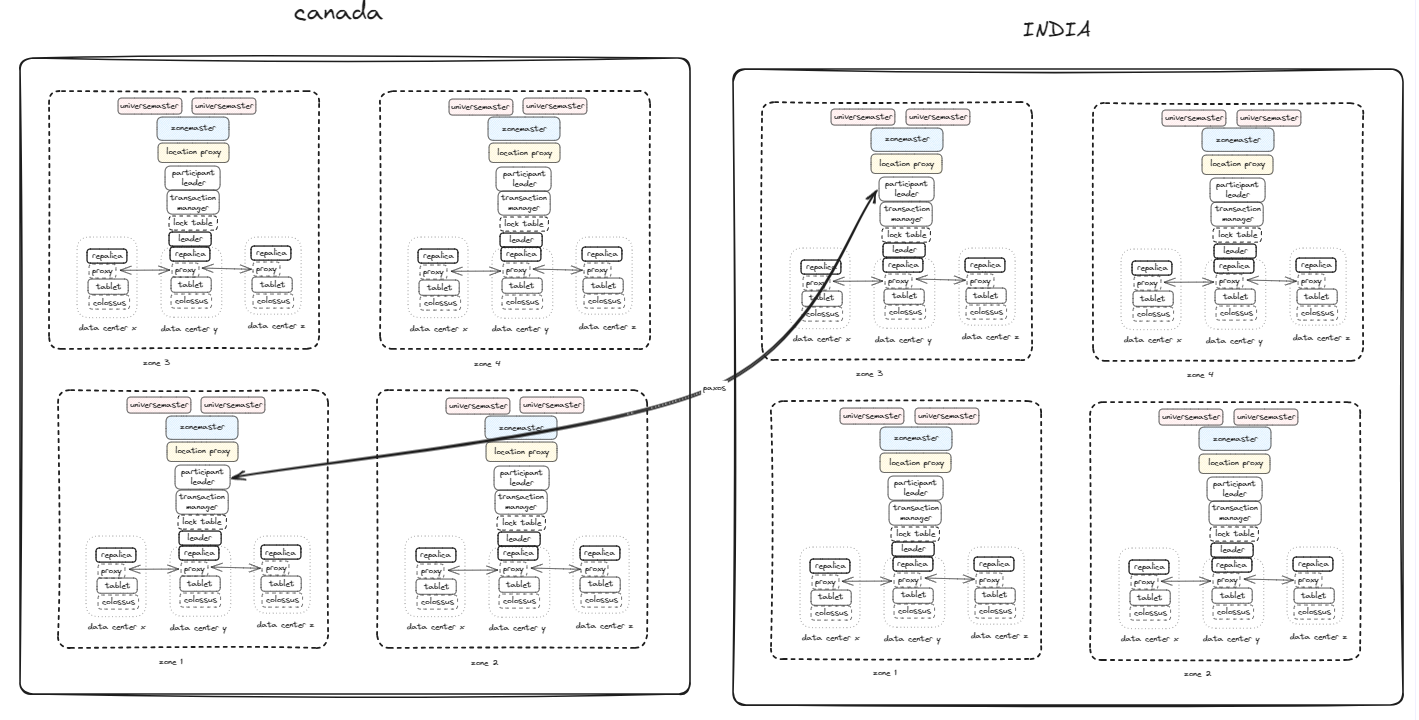
Spanner architecture
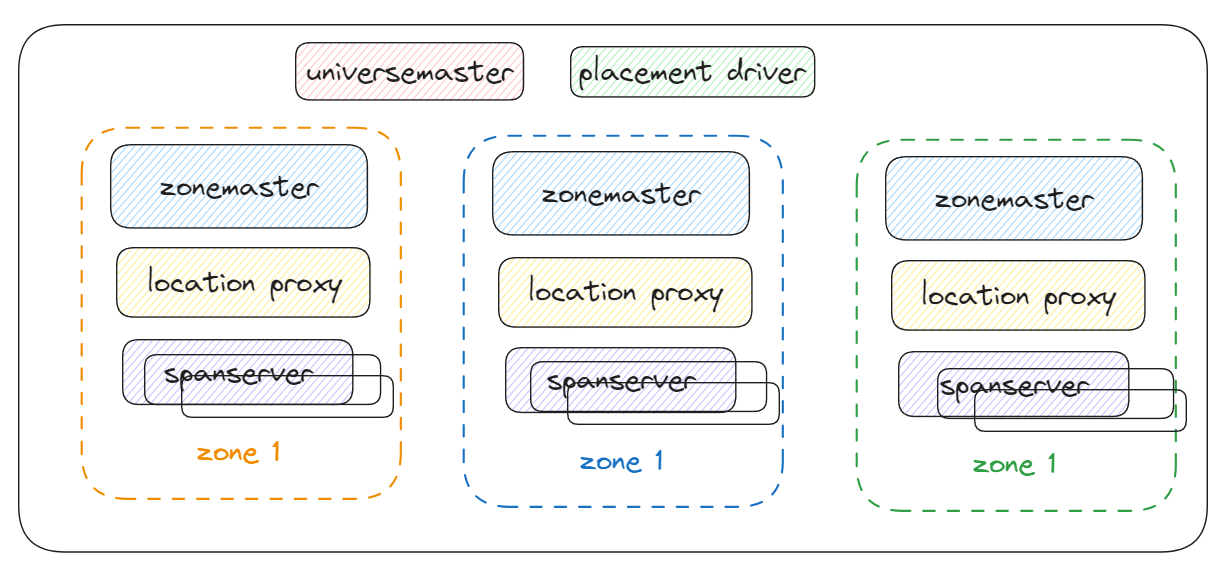
A deployment is called universe
Spanner organized as set of zones
Zones
Unit of Administrative deployment
Can be turned off
Can be added to removed rom running system as new datacenters are brought into service
Unit of physical isolation
Datacenter can have one more more zones
Figure illustrates that Servers in a spanner univers
A zone has one zonemaster between 100’s and 1000’s of span servers
Location proxies are used by clients to locate the spanservers assigned to serve their data.
Universe master and placement driver are singletons
Univers master is primarily a console that displays status information about all the zones for interactive debugging.
Placement driver handles automated movement of data across zones ont the time scale of minutes
Placement driver periodically communicates with the span server to find data that needs to be moved for replications or to balance load
Spanner software stack
How replication and distributed transaction have been layered onto our bigtable-based implementation
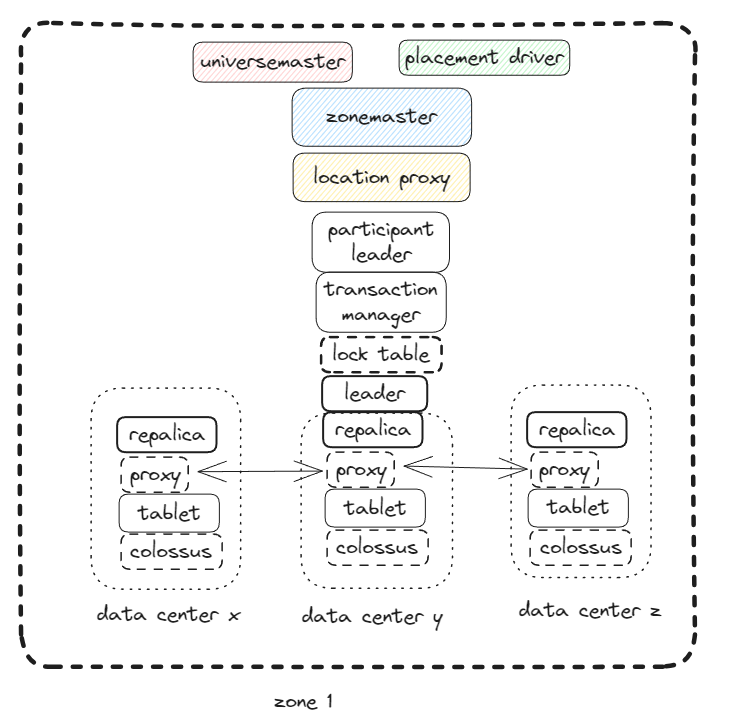
tablet
At the bottom each spanner is responsible for between 100 and 1000 instances of a data structure called a tablet.
Tablet is similar to bigtable’s tablet abstraction
Tablet implements, bag of mappints
( Key:String, timestamp:int64) → string
Multi-version database ( not a key-value store )
Spanner assigns timestamps to data which is an important way in which spanner is more like multi-version database than a key-value store
B-Trees-liek files
Table’s state is stored in set of b-trees like files and WAL ( write ahead log ) all ona distributed file system called colossus
Colossus
Successor to the google file system
Replication ( PAXOS )
Each spanserver implements a single paxos state machine on top of each tablet
Paxos state machine
State machine stores it’s metadata and log in it’s corresponding tablet.
Leader support
Long lived leader with time based leases
Logs every Paxos write twice
Once at tablet log
Paxos log
Paxos state machine are used to implement a consistently replicated bag of mappings.
Bag Mappings
Key-value state of each replica is stored in it’s tablet
Writes
A write must init a the paxos protocol at the leader
Reads
A read access state directly from the underlying tablet at any replica which is up to date
Paxos group
Set of replicas is collectively a paxos group
Lock table ( Two-phase locking )
Spanserver implements lock table ( concurrency control )
Maps ranges of keys to lock state
Designed for long-lived transactions
Lock efficiency
Long lived paxos leader is critical
Optimistic concurrency control
Is not used and not suitable for long lived transaction in presence of transaction conflicts that requires synchronization
Synchronization
Transactional reads,
Acquiring locks in the lock table
Other operations by pass the lock table
Transaction manager ( distributed transactions )
Spanserver implements transaction manager to support distributed transaction.
Transaction manager implements participant leader
Participant slaves
Other replicas in the group
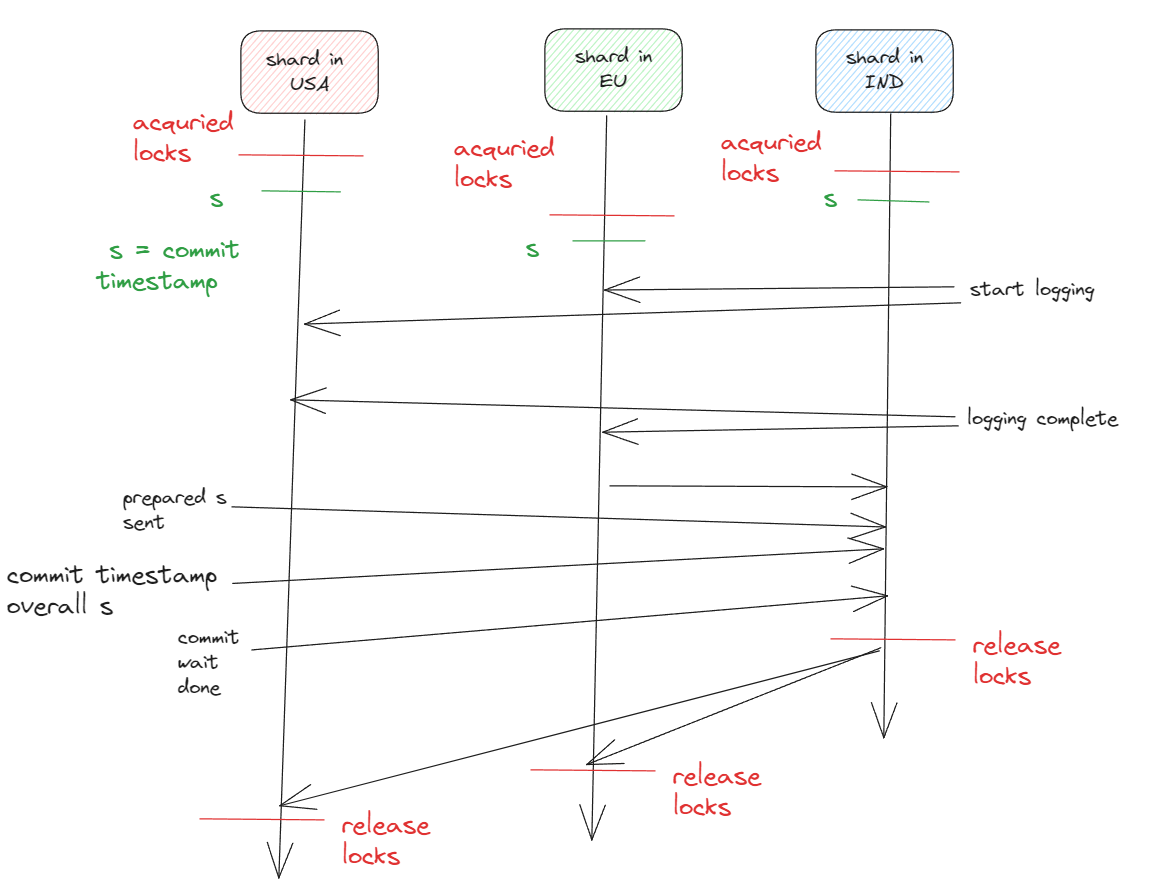
Two-phase commit
A transaction involves more than one paxos group, those groups leader coordinates to perform two-phase commit
Co-ordinator leader
Participant leader of that group will be referred to as the coordinator leader.
Coordinator slaves
Slaves of that group referred to coordinator slaves
State of each transaction manger is stored in paxos group, ( provides replication )
Directory and placement
Todo : add the diagram
bucketing abstraction
Spanner implements support a bucketing abstraction called directory ( bucket )
Set of contiguous keys that share a common prefix
Helps applications to control the locality of their data by choosing keys carefully.
Data
Data is placed in a directory referred to as a unit of data placement.
Data movement
Data moved directory by directory in case of data movement. Between paxos groups.
Frequently accessed data is put together in the same directory
Generally data is moved closer to the accessor
Directory can be moved while client executing operations.
Assumption
50mb of directory can moved in few seconds.
Movedir
Background task used to move directories between paxos groups
Also used to add or remove replicas to paxos groups
Movdir Registers the data movement once that is done it uses a transaction to move data and update the metadata for the two paxos groups.
Application configuration
Placement can be configured
Number and types of replicas can be configured
Fragments
Shared a directory into multiple fragments if it grows too large
TrueTime

Underlying time reference used by truetime are GPS and atomic clocks
Design faults
Incorrect leap seconds handling and spoofing
GPS failures
Antenna
Receiver failure
Local radio interference
Correlate failures
Atomic clocks
Over a long period of time can drift significantly due to frequency error.
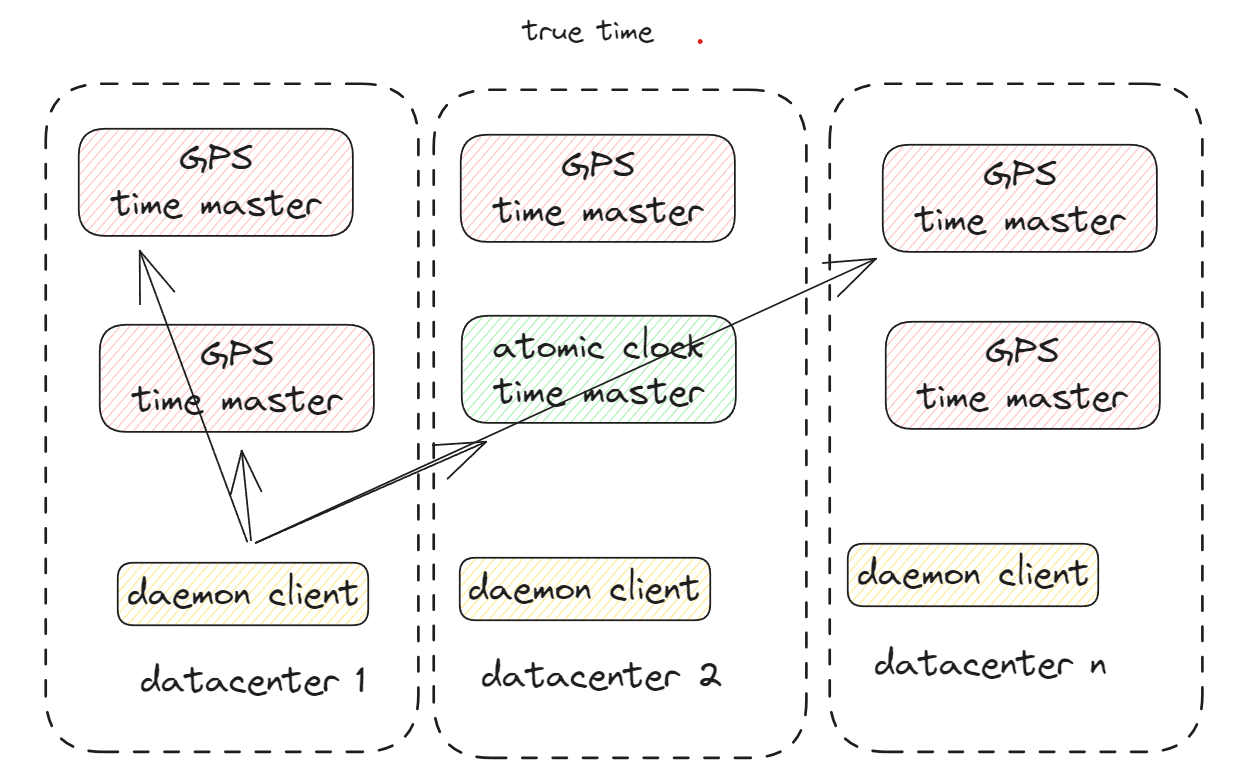
Implementation
Time master machines per datacenter
Time slave daemon per machine
Majority master have GPS receivers with dedicated antennas physically separated
Other type of master armageddon master
Uses atomic clocks, which are not expensive
Cost almost as GPS master
Time synchronization
Masters compared against each other
Cross checks the rate for advances time against it’s own clock and corrects it’s self.
Marzullos algorithm is being used with daemons.
Concurrency control
True time is used to guarantee the correctness properties around concurrency control.
This properties are used to implement features such as
externally consistent transactions,
lock free read-only transactions
Non-blocking reads in past
A transaction to read see exactly the effects of every transaction that has committed as of t.
Paxos writes are different to transaction writes in spanner clients
Timestamps management
| Operation | Concurrency Control |
|---|---|
| Read-Write Transaction | pessimistic |
| Read-Only Transaction | lock-free |
| Snapshot Read, client-provided timestamp | lock-free |
| Snapshot Read, client-provided bound | lock-free |
Read write transactions
Read only transactions ( pre-declared snapshot-isolation transactions )
Snapshot reads
Implementation
Standalone writes are implemented as Read-write transactions
Non-snapshot standalone reads are implemented as Read-only transactions
Read-only transactions have performance benefits of snapshot isolation
performance benefits
Without locking
Snapshot read
Read in the past that executes without locking.
Timestamps
To avoid buffering results inside a retry loop.
In case of server failure clients can internally continue the query on a different server by repeating the timestamp and the current read position.
Paxos leader leases
Implementation uses timed leases to make leadership long-lived
Step 1
A potential leader sends requests for time lease votes
Step 2
Once receiving quorum lease votes the leader knowns it has a lease
Step 3
A replica extends it’s leas vote implicitly on a successful write
Step 4
Leader request leas-vote extensions if they are near expirations
Assigning timestamps to Read write transactions and Read-Write Transactions
Transaction reads and writes use two-phase locking, Before locks and after locks in between we can assign timestamps.
Disjointnes invariant :
A leader must only assign timestamps within the interval of it’s leader lease.
External consistency invariant
A transaction T2 occurs after the commit of transaction T1,
Then the commit timestamp of T2 must be greater than the commit timestamp of T1
Define the start and commit events for a transaction Ti
e(i,start)
e(i,commit)
Commit timestamp T(i) by S(i)
Invariant
T abs( e(1,commit) < T abs(2, start) => s(1) < s(2)
Read-Write Transactions
Writes occur in a transaction are buffered at the client until commit.
Transaction reads do not see the effect of the transaction writes.
Reads within read-write transaction use wound wait, to avoid deadlocks
Client issues reads to leader replica of a group, achievers read locks and then reads the most recent data.
Sends keepalive message to prevent leaders from timing out in case of transaction still remain open
After all reads and buffers writes, it starts two-phase commit
Assigning Timestamps to read only Transactions And Read-Only Transactions
Read-only transaction executes in two phase, Assign timestamp S(READ),Execute the transactn’s reads as snapshot reads at S(READ), Snapshot reads can execute at any replicas that are sufficiently up-to date
Simple assignment of S(READ) = TT.NOW().LATEST, At any time after the transaction start preserve external consistency.
Paxos leader
Leader assign S(READ) and execute the read